简介
GPU Performance Background User’s Guide 是英伟达官方写的性能优化背景知识指南。主要介绍了以下几方面内容:
- GPU 基本架构
- GPU 执行模型
- 如何评估是 compute bound 还是 memory bound ?
- 评估深度学习中常见算子
GPU 基本架构
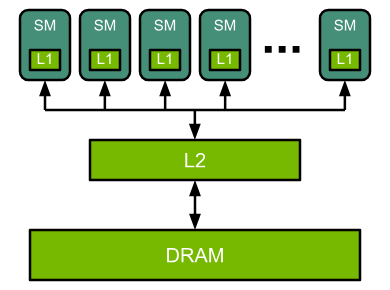

如何计算计算操作的吞吐率 FLOPS:SM 核数量 * SM 核主频 * 表格中某种类型操作每个时钟周期的乘加运算数量 * 2(乘+加)
example: A100 TF32 FLOPS = 1.41 GHz * 108 SM * 512 * 2 ≈ 156 TFLOPS
图中 SM 核分为 CUDA Cores 和 Tensor Cores,Tensor cores 可以用来对小矩阵块进行操作。非矩阵操作则还是通过 CUDA Cores 来执行
GPU 执行模型
因此 GPU 会将计算任务划分成多个 thread-block,每个 thread-block 交给不同 SM 核并发执行。每组并发执行的 thread block 被称为 “wave”。
可能会存在尾部效应,即最后一组任务用不满 SM 核。所以线程块数量最好是 SM 核的数倍,以满足足够的并行计算利用率。

评估性能瓶颈
给定一个简化的计算场景:一个函数从内存读取输入,执行计算,将输出写入内存。
计算耗时:Tmath = ops / BWmath
内存IO耗时:Tmem = bytes / BWmem
Compute bound 场景(反之则为 memory bound):
Tmath > Tmem
ops / BWmath > bytes / BWmem
ops / bytes > BWmath / BWmem
ops / bytes 通常被称为 Arithmetic Intensity,
右侧则是规格参数之比
评估深度学习中常见算子
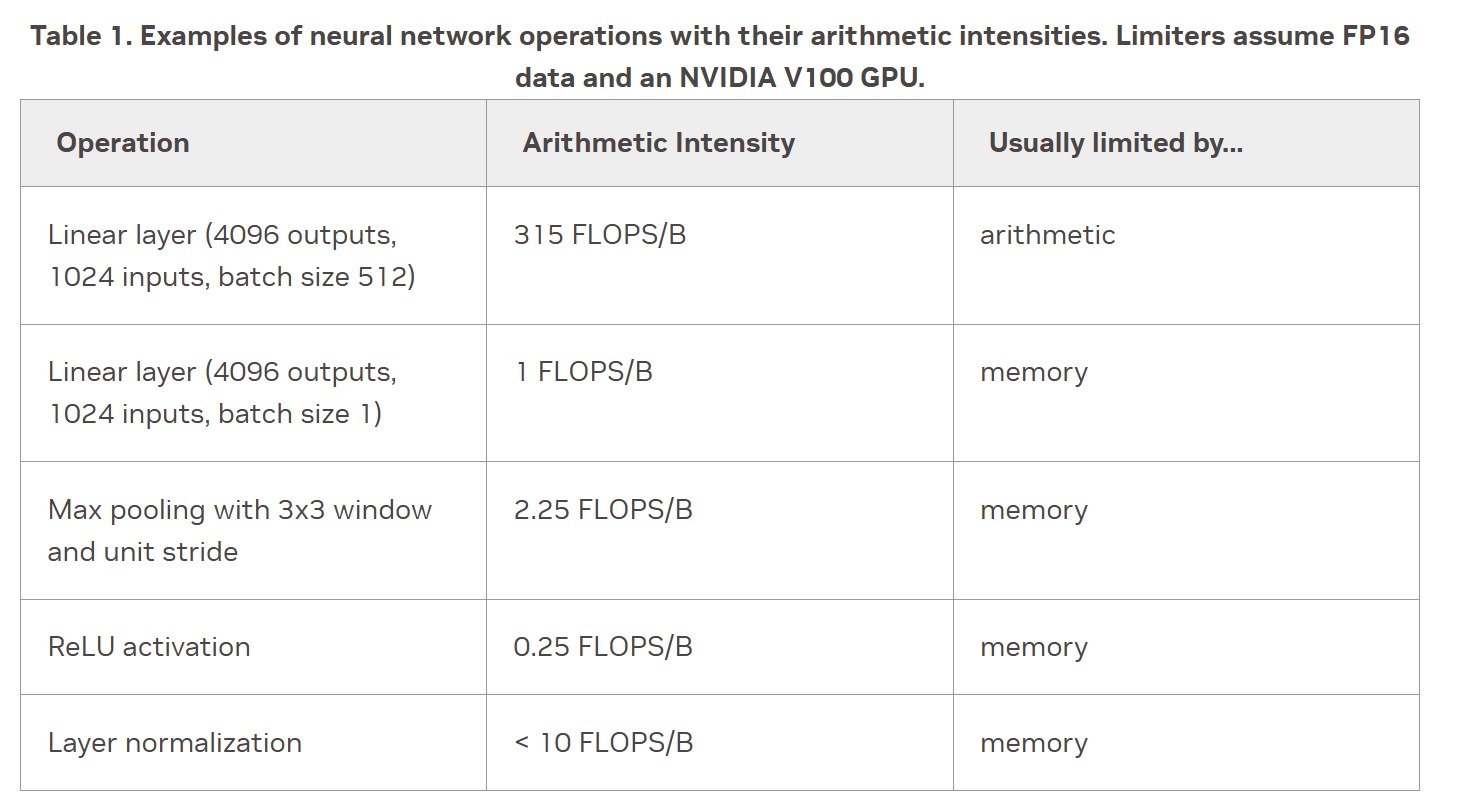
总结评估瓶颈的步骤
查 GPU 规格,还有算子操作数,输入输出大小
计算 Arithmetic Intensity
估算 thread block 数量和大小。如果 tb 至少比 SM 数量高出大约 4 倍,且每个线程块由几百个线程组成,则并行度很可能够了。
瓶颈相关关键词:计算并行性、compute bound、memory bound