Unified memory(UM) 是在 cuda 6.0 被引入的统一 CPU、GPU 内存空间管理的技术,使得同一内存地址能够同时被 Host 和 Device 认出,且能够由 cuda 来自动进行内存迁移管理。
基于 UM 可以简化 CPU-GPU 之间 cuda kernel 编程,同时也能非常方便地进行显存超分。但功能上是能轻松实现,后续的性能优化则是需要好好考虑的。
Unified memory(UM)简介
UM 实现方式就是用 cudaMallocManaged api 来替代原有的 cudaMalloc api 调用,并且在算子执行完后需要额外添加 cudaDeviceSynchronize 进行一下内存同步确保 kernel 执行完成。
早期实现 UM 的大致原理是在 CPU 上申请的内存,在 GPU 将要用到这块内存时会触发 page fault 进行内存搬运。后面则做了优化,在通过 cudaMallocManaged 申请内存时先不实际申请物理内存,而是等到第一次访问该内存时再进行分配,或者可以通过 cudaMemAdvise 指示驱动分配在哪,也可以通过 cudaMemPrefetchAsync 来提前做预取迁移。这样主要是为了减少影响性能的 page fault 次数。
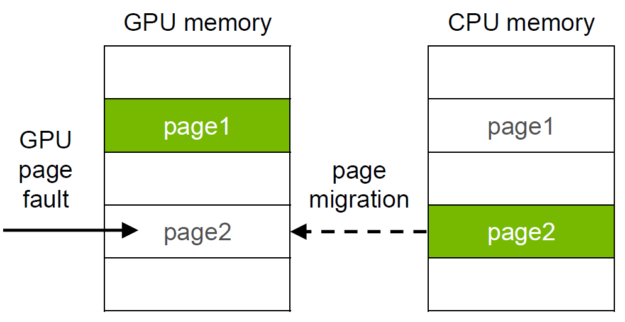
UM 的性能调优
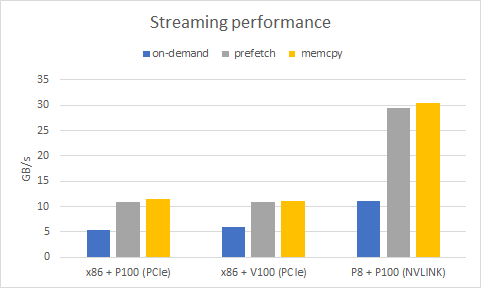
有没有预取所带来的性能差异还是很大的,Maximizing Unified Memory Performance in CUDA 提供了一组对比数据,可以看到不带预取,性能会劣化一倍多;而带了预取则能近似达到不用 UM,直接进行 memcpy 的效果。
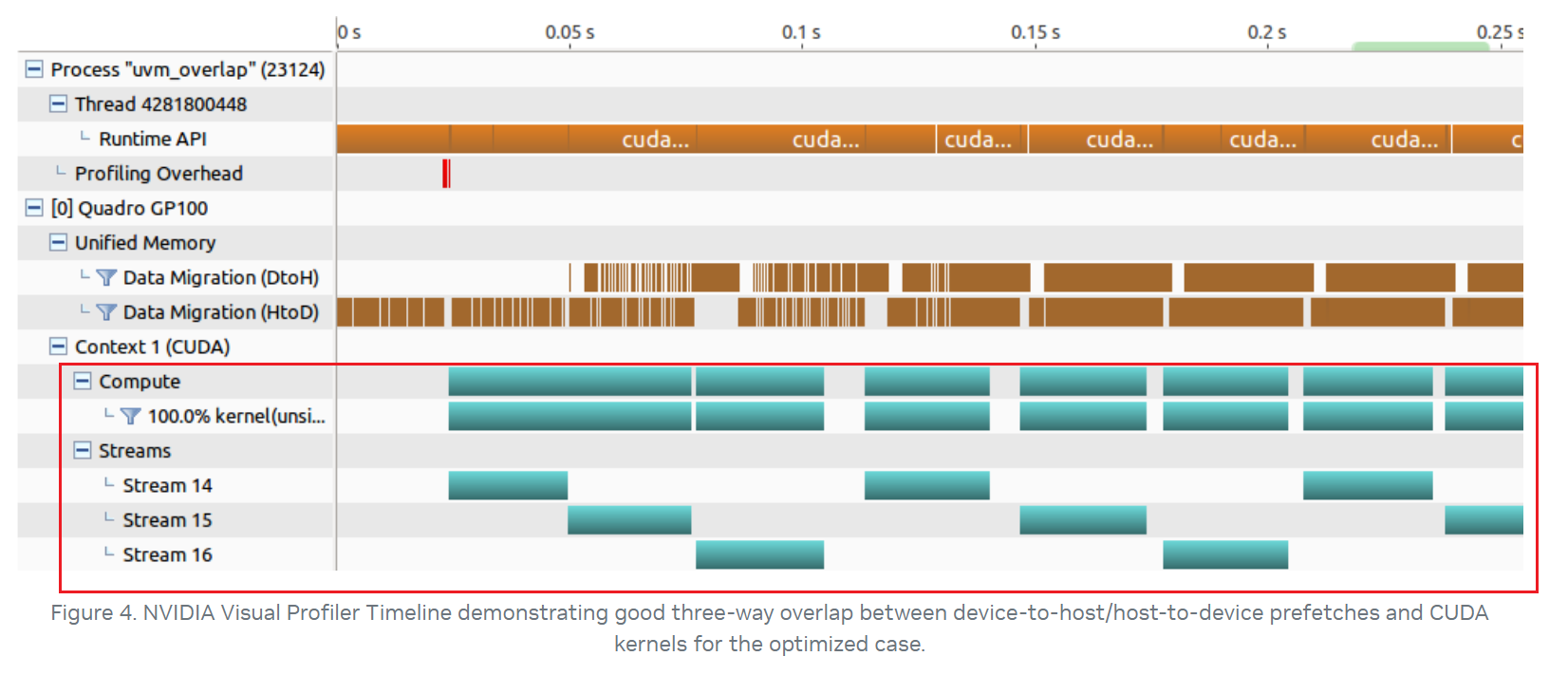
UM 的性能调优还需要考虑如何将异步的预取和 kernel 执行进行 overlap。因为 cudaMemPrefetchAsync 是个异步操作,且相比 cudaMemcpyAsync 前面还会多一些诸如查表的操作,这可能会导致在一个繁忙的 stream 中,将预取放到一个后台线程中延后操作。所以对于关键路径上的预取操作需要考虑将其放在单独一个 stream 上进行操作,以下是一个例子:
1 | // prefetch first tile |
显存超分(TODO)
UM 除了简化编程模型之外,他的自动内存搬运能力还能够天然地做到显存超分(oversubscription)的能力,通过 Host 侧内存来拓展 GPU 侧内存上限。不过由于他用到的 page fault 机制,还是需要做好性能优化才能好用。cuda-sample 项目(Benchmark for UVM oversubscription tests)中包含了对于超分的 microbench。Benchmark for UVM oversubscription tests 这篇文章做了介绍。
超分性能测试
读内存模式
该 microbench 主要测试了三类模式的内存读取内核:
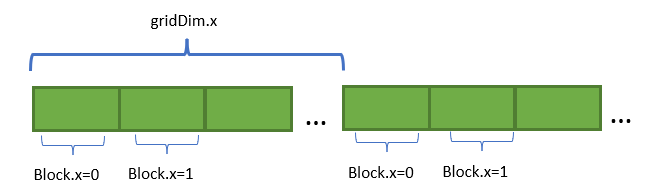
- Grid-stride:每个竖切是一个 block,顺序读
1 | template<typename data_type> |
- block-stride:每个横切是一个 block,顺序读
1 | template<typename data_type> |
- random-per-warp:每个 warp 的每个迭代会随机读取一个随机页面。

性能结果及优化
1. 基准测试,除了 cudaMallocManaged 之外不做任何其他操作。
1 | cudaMallocManaged(&uvm_alloc_ptr, allocation_size); |
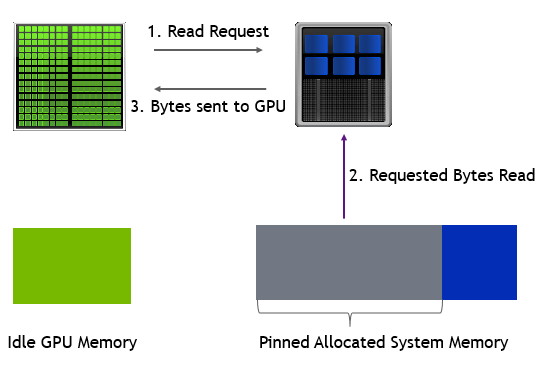
在这种情况下,GPU 内存没占满的时候触发 page fault 的流程如左下所示,触发 H2D 的传输;占满的时候如右下所示,会先驱逐其他内存页到 Host 侧,然后再触发 H2D 的数据传输。
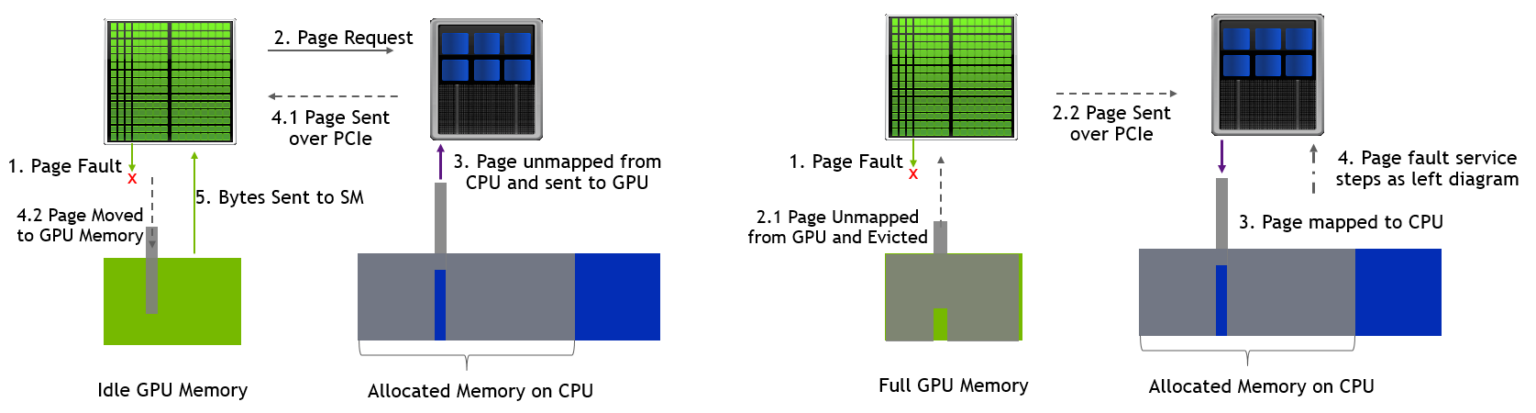
通过 nsight 观察到的内存执行情况如下所示:

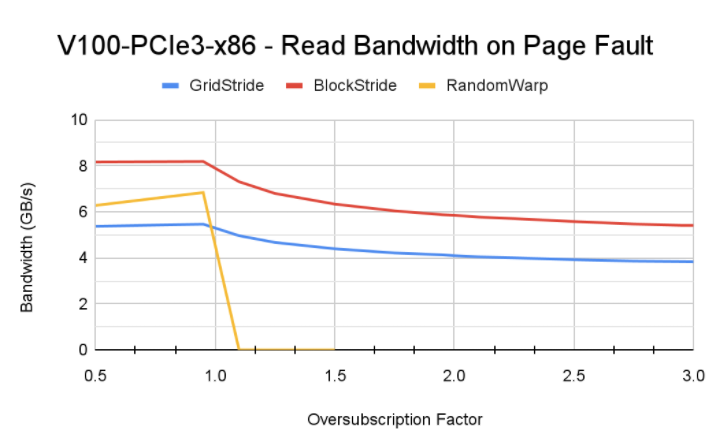
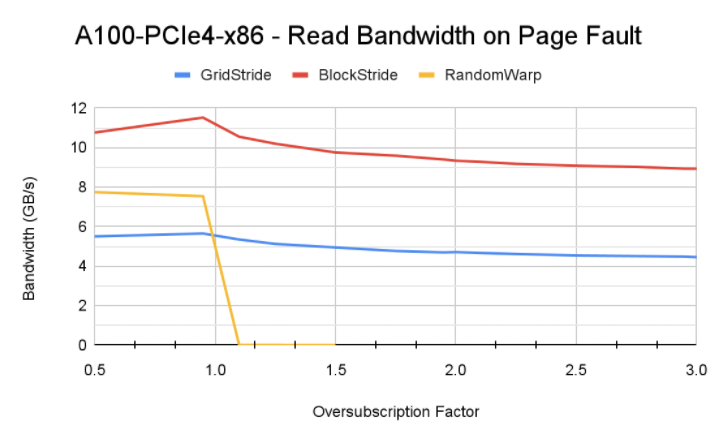
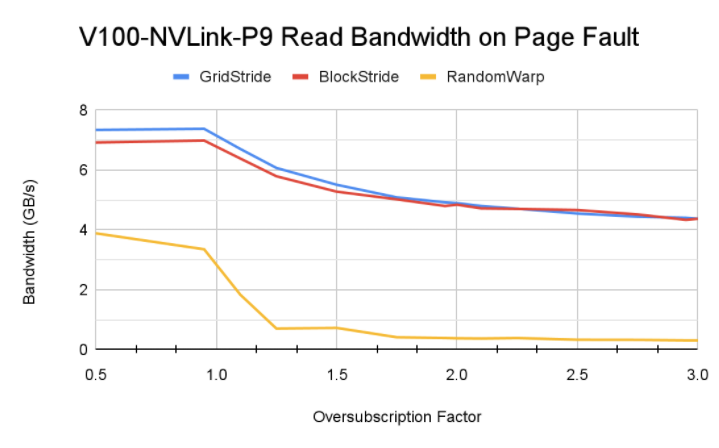
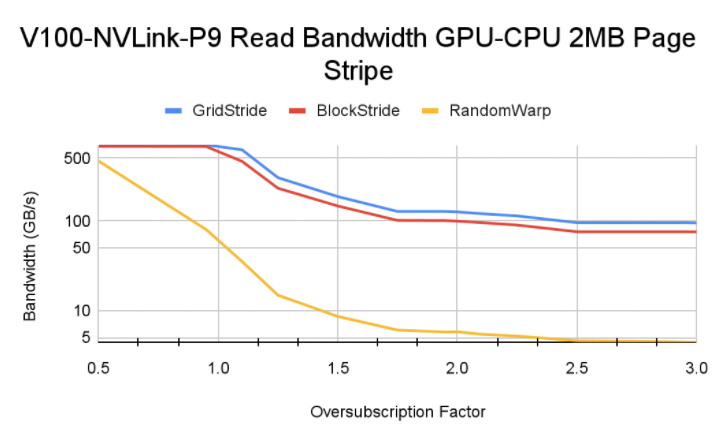
性能情况如下,可以看到:
- block-stride 跨页少,触发 page fault 少,是内存访问性能最优的;
- 随机读性能远低于顺序读,当然本身这种方式就是会比较慢;
- 不同架构由于互联能力和 SM 核数量不一样,触发的换页次数以及对性能的影响页不一样。
2. 优化1:通过 cudaMemAdvise 建立 Host 与 Device 之间的映射关系,实现 zero-copy
1 | cudaMemAdvise(uvm_alloc_ptr, allocation_size, cudaMemAdviseSetPreferredLocation, cudaCpuDeviceId); |
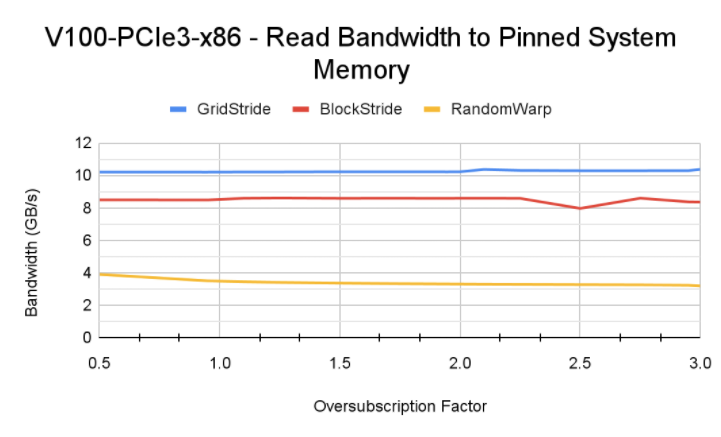
可以看到这样性能远高于优化前,能达到读 Host 的性能水平(受限于 CPU-GPU 之间带宽上限)。
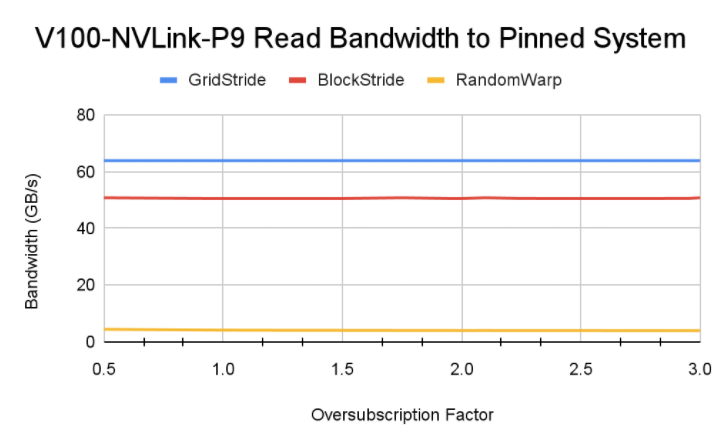
3. 优化2:CPU-GPU 之间进行 DMA
有两种实现方式:
cudaMemPrefetchAsync+SetAccessedByhint- 通过
SetPreferredLocation+SetAccessedBy手动设置对超分部分的内存页设置 hint,建立 CPU-GPU 之间的映射关系
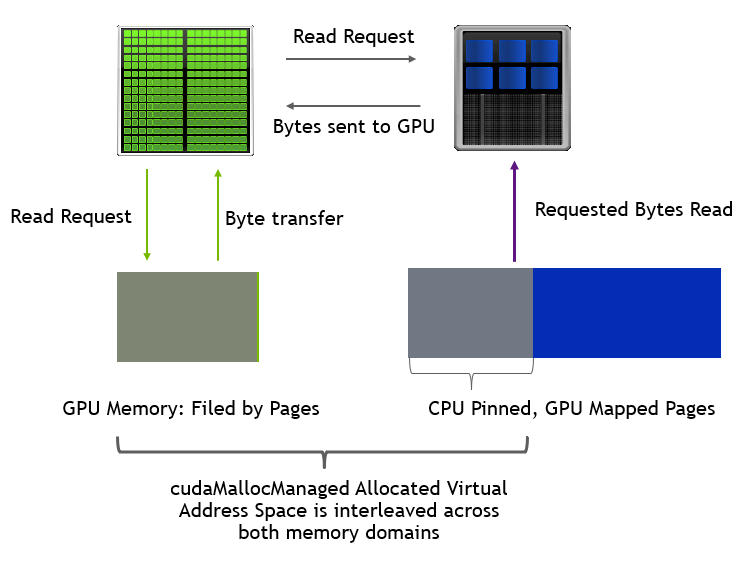
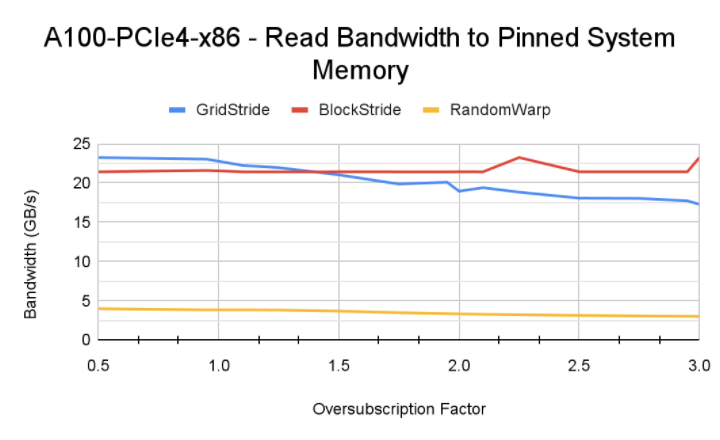
可以看到这种模式性能能在超分比例小于 1 的情况下达到 GPU 直接读显存的效果,而随着超分比例增大,性能会劣化到读 Host 的性能水平。
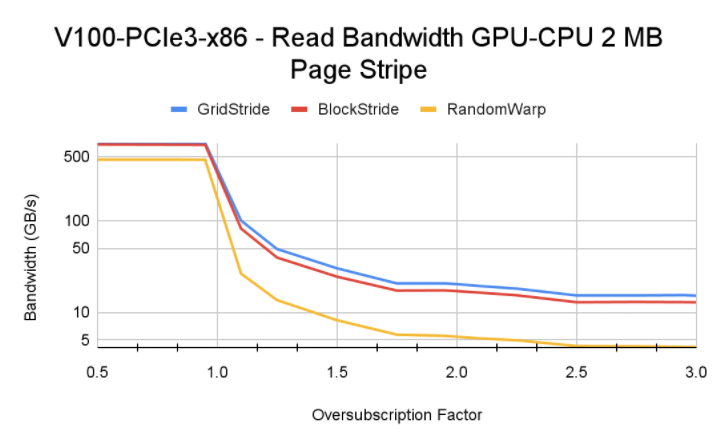
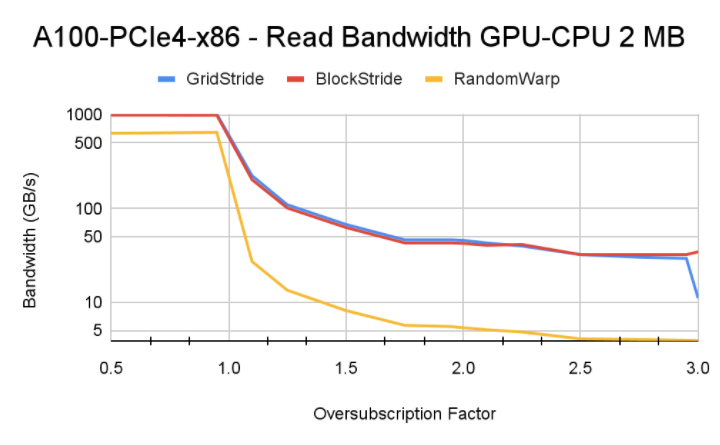
总结
显存超分简单,性能调优难,需要综合考虑算子 workload、GPU 架构等因素。
参考引用
Unified Memory for CUDA Beginners
Improving GPU Memory Oversubscription Performance