跟踪 NCCL 新版本重要特性
2.28.3
Device API
- 新增实验性质的 Device API,可以将 NCCL 通信直接集成进算子中。
API 文档:NCCL device API
- Symmetric 算子重新用 device API 实现了一遍
Copy Engine
通过使用 CE(Copy Engine),降低了单个 (MN)NVL 域内 SM 用量。当用 ncclAlltoAll, ncclScatter, and ncclGather 时会用更少的 SM 核。
使能该特性需要将 buffer 注册金 symmetric windows 中,并使能 NCCL_CTA_POLICY_ZERO 标志位
其他
新增 host 侧集合通信 API: ncclAlltoAll, ncclScatter, and ncclGather.
在 Blackwell 架构上,将 max CTA 数量从 32 降低到 16,这样理论上会降低 50% SM 开销,但可能会导致性能降低
新增
NCCL_NETDEVS_POLICY环境变量,支持自定义配置使用网卡的数量(以前默认是自动模式)

2.27.3
技术博客:enabling-fast-inference-and-resilient-training-with-nccl-2-27
Symmetric memory API 和相关实现
- 添加 symmetric memory API(
ncclCommWindowRegisterwith theNCCL_WIN_COLL_SYMMETRICflag,ncclCommWindowDeregister), 默认打开。
example:
1 | ncclCommWindowRegister(ncclComm_t comm, void* buff, size_t size, |
原理: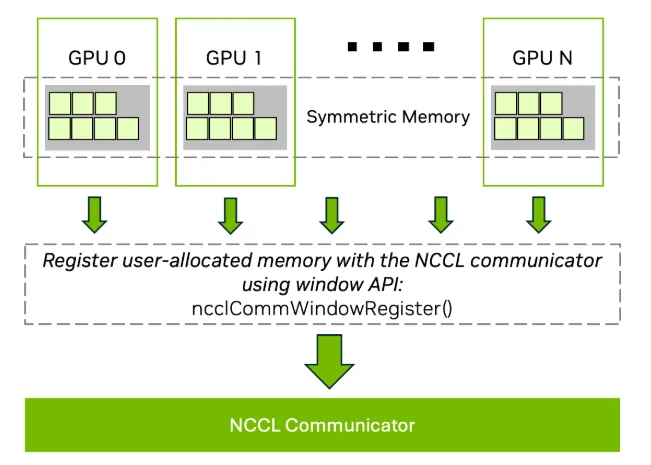
该特性允许不同 GPU 中相同 VA 的 buffer 进行通信加速: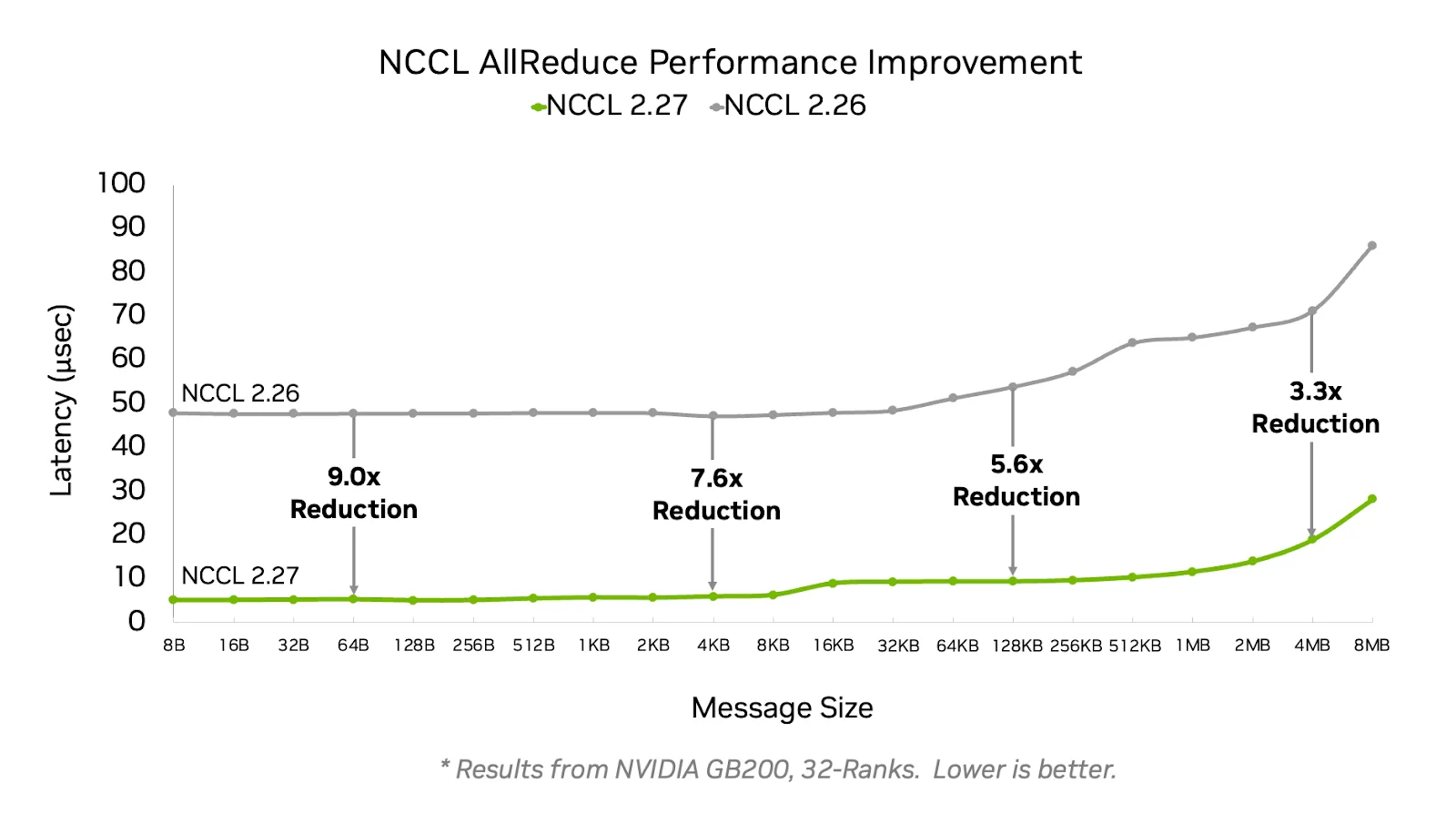
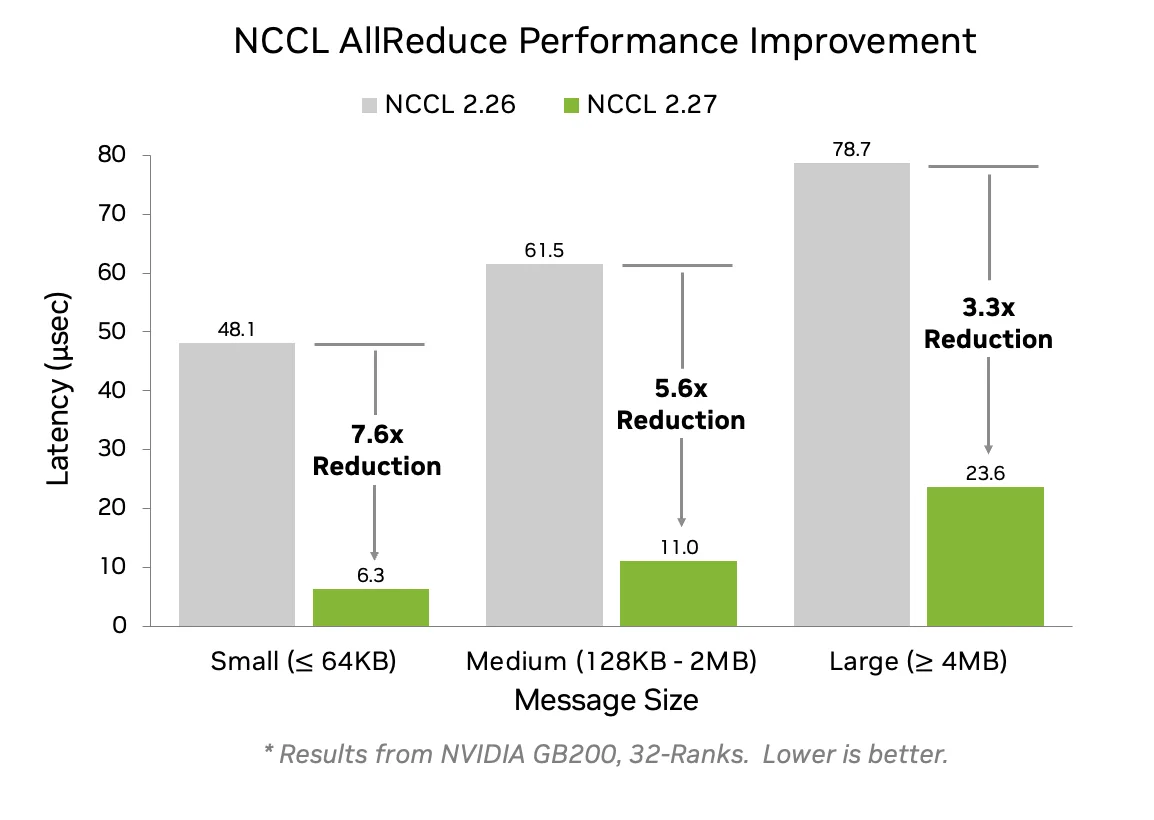
该特性可以被用在DGX/HGX/NVL72 等系统中的 NVL 域内
ncclCommShrink
- 新增 ncclCommShrink api,支持将一个指定 rank 踢出,创一个新的 communicator。
example:
1 | int excludeRanks[] = {1}; // Rank to exclude |
其他
- 对 AllGather 和 ReduceScatter 支持 SHARP,使能在网 reduction 操作来降低 SM 核使用。
- 支持 per communicator 粒度的 NCCL 行为微调。