本文是多篇知乎文章的学习小结:
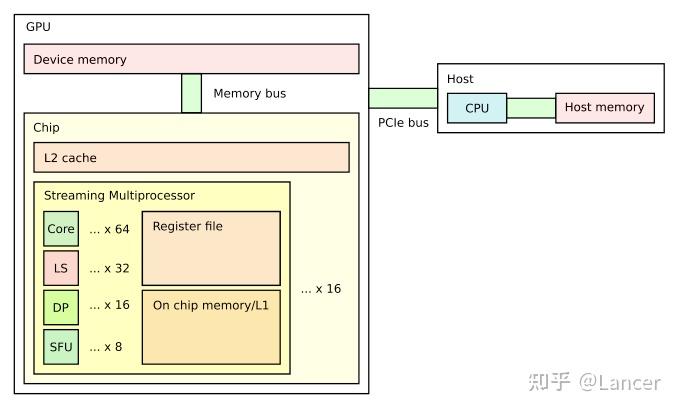
GPU 硬件组成
GPU 基本执行单元 stream processor(sp),又叫 core 或者 thread,一般 32 个 sp 组成一个 warp。几个 warp 组成一个 stream multiprocessor(SM),SM 组成 GPU。
GPU 自带寄存器,同一 SM 中 SP 可以共享 shared memory,constant cache,texture cache,最后所有 sm 可以共用 hbm
CUDA 编程模型
编程层次:Gird -》 Block -》 Thread
包含内置变量 gridDim 表示三维线程网络的大小。内置变量 blockDim 表示线程区块大小,blockIdx 和 threadIdx 表示当前 block/thread idx。
Tiling 技术
Tiling 就是利用 shared memory 去降低 device memory 的访问次数。
从矩阵乘开始说起,首先是 Host 版本的
1 | void MatrixMulOnHost(int m, int n, int k, float* A float* B float* C) |
然后是 Kernel 版本的:
1 | __global __ void MatrixMulKernel(int m, int n, int k, float *A,float *B, float* C) |
可以看到矩阵 A 和 B 被访问了 n 次。性能优化首先可以将 A 分次从 global memory 加载到 shared memory 中。
1 | __global__ void MatrixMulKernel(int *d_M,int *d_N,int *d_P,int m,int n,int k) |
GPU 编程优化综述
如何使用 shared Memory:
1 | __shared__ float sdata[256]; |
如何操作 warp 内使用不同线程数操作:
1 | if (threadIdx.x % 2 == 0) { |
Thread block 编程抽象,一个 thread block 被调度到某个 SM 上后,会全程驻留到 SM 核上直到完成。一个 SM 可以运行多个 block,他们的 shared memory 是隔离的。
Registers 是线程私有的存储空间。当前 GPU 支持 Warp shuffle 允许同一 warp 内线程直接交换寄存器的值,无须写入 shared memory 中。
warp 并行:
- 当一个 warp 发生长延迟操作时,该 warp 会被挂起,调度器立即切换到另一个 ready 的 warp 执行。
- 一个 warp 内部有多个独立指令可以重叠执行。
优化技术
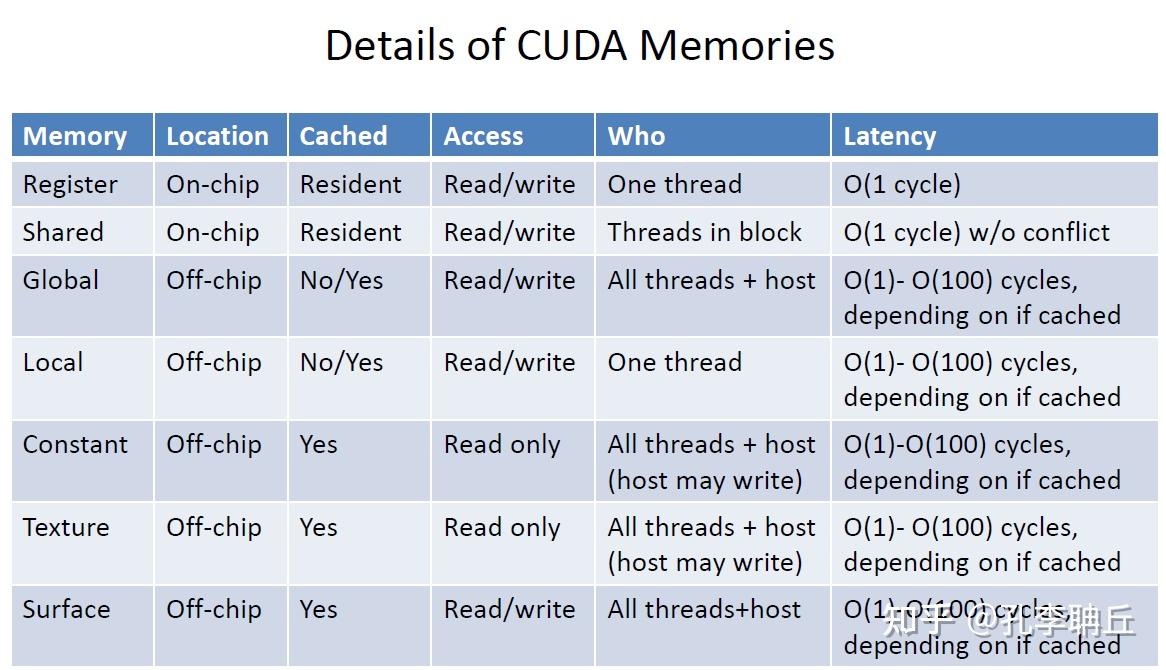
1. Memory Access
提升访存速率,优化目的时最大化数据重用,最小化对慢速设备内存(Off-chip)的访问,主要分为两类:
On-chip:高效利用片上资源(shared memory,register,L1/L2 cache)
shared memory
关键挑战:Bank conflict,shared memory 被划分成多个 bank,如果一个 warp 32 个 thread 访问同一个 bank,会发生冲突,导致串行化访问
解决方案: padding、reordering data、remap threads to data
Constant Memory
只读内存,有专用的广播机制
用途:存储常量,对所有线程广播,一次访问即可
Texture Memory
只读内存,针对 2D 空间局部性进行了优化
用途:图形应用,但也被用于 GPGPU,如处理边界,缓存不规则访问,自动数据类型转换
Warp 函数
- Warp-Vote Function:允许 warp 内线程对某个条件进行投票(__any_sync(), __all_sync()),实现五共享内存的快速同步
- Warp-Shuffle(__shfl_sync()):允许 warp 内的线程直接交换寄存器值,无需经过 shared memory。实现了寄存器级别的直接通信。极大地减少了对 shared memory 的依赖和 bank conflict 的可能性。
寄存器阻塞(Temporal Blocking)
- 循环中重复使用的数据保存在寄存器中。确保热点变量都驻留在寄存器中
减少寄存器使用
过多地使用寄存器会降低 occupancy,导致 register spilling 到全局内存
优化技术:
- 减少临时变量、使用指针算术
- 小数据类型打包
- 重计算(常与 Kernel fusion 结合)
- 强制编译器限制寄存器使用
Off-chip:高效访问设备内存
合并访问
调整数据布局,从 Array of Structs,转为 Struct of Arrays
调整线程组织:确保线程 ID 与数据索引对齐
使用共享内存作为中转:先用合并方式从全局内存加载到 shared mem 中
数据填充,避免 bank conflict 和合并问题
内核融合(Kernel Fusion)
多个连续执行的小 Kernel 合并成一个大 Kernel
软件预取
提前将下一阶段需要的数据从全局内存加载到 shared memory 或寄存器中。
常见模式:双缓存,一个 buffer 用于当前计算,另一个用于预取下一阶段的数据
压缩数据
预计算 (Precompute)
2. Irregularity 不规则
不规则访问,不规则分支,不规则负载
循环展开(Loop Unrolling)
1 | // 原循环 |
Reduce Branch-Divergence (减少分支发散)
问题原因,一个 warp 必须 lock-step,如果 warp 内线程因为 if/else 走不同路径,GPU 会串行执行两个分支,未被执行的分支会被屏蔽
优化技术:
- 用算术运算/查找表替代 if/else
- 通过排序、分组改变数据布局,相似行为线程聚集一起
- 算法展平,避免多重嵌套
- 分支分发:公共代码移出分支
评估一个 kernel 的性能时,nsight compute 中的 branch_efficiency 是一个关键指标。理想值接近 100%。
Sparse Matrix Format
需要设计一种数据格式既能压缩存储,又能适应 GPU 并行访问
主要格式:
- ELL(ELLPACK):每行填充至相同长度,形成规则的二维数组
- CSR(Compressed Sparse Row):存储非零值数组,列索引数组和行指针数组。优点是访问紧凑,缺点是访存不规则,容易导致 warp divergence
- hybrid:结合 ELL 和 CSR 有点
- 自适应格式:SELL-C-o,通过排序分块,将相似长度的行分组
Kernel Fission(核分裂)
将多个 if 分支的复杂 kernel 拆分成几个专门处理特定情况的 Kernel
减少冗余工作
循环剪枝等
3. 平衡
指令流平衡
用 float4 等向量化的数据类型
Fast math function
使用硬件加速的、精度较低但更快的数学函数__sinf()、__expf() 等
warp-Centric Programming
将warp 作为基本计算和调度单位,而不是单个线程。
用 __syncwarp() 替代 __syncthreads()
调整 block 大小,warp 工作量到均衡
Load Balancing
Warp 内 :通过 stream compaction 等技术,让活跃线程聚集。
Block 内 :使用 global worklist 或 work-stealing。
SM 间 :对于不规则应用,使用 persistent threads 模型,让线程长期存活并动态获取任务。
同步平衡
减少同步、减少原子操作、通过 Cooperative Groups 允许定义一个跨越多个 block 的线程组,实现跨块同步
4. CPU-GPU 交互
主机通信
减少通信次数、压缩数据、统一内存
动态并行
允许 GPU 上线程直接启动新的 Kernel,无需返回 CPU
优化传输机制
Pinned Memory:提升cudaMemcpy带宽
Mapped Memory:主机内存映射到 GPU 地址空间,允许 GPU 直接访问(cudaHostGetDevicePointer)
Stream and Overlapping:
- 计算通信overlapping、通信-通信 overlapping
多 buffer:多个 buffer 多个不同操作并行
CPU/GPU 任务协同
分解成多个任务,分配给 CPU GPU 并行执行,让两者负载均衡
基于特征使用不同优化技术
计算密集型
如 FFT、物理模拟
适用技术 :
Reduce Redundant Work :避免重复计算,让宝贵的计算资源用在刀刃上。
Loop Unrolling :暴露更多独立指令,提升 ILP。
Varying/Resize Thread Blocks :调整并行粒度,更好地利用 SM 资源。
Vectorization :使用 float4 等向量指令,一次完成多个计算。
Fast Math Functions :用精度换速度,减少对 SFU 的占用。
Reduce Atomics :避免昂贵的原子操作阻塞计算流。
Auto-tuning :自动化地搜索最优的配置参数。
内存密集型
如向量加法,稀疏矩阵乘
适用技术 :
Use Dedicated Memories :用 shared memory 或 texture memory 缓存数据。
Coalesced Access :确保 warp 的访存是合并的。
Spatial/ Register Blocking:通过分块提高数据局部性。
Kernel Fusion :减少 kernel 间的中间结果存储。
Software Prefetching :提前加载数据,隐藏延迟。
Use Warp Functions :用 warp shuffle 替代 shared memory 通信,减少内存压力。
Reduce Synchronization :减少 __syncthreads() 带来的 stalls。
Warp-centric Programming :让 warp 作为工作单元,更好地隐藏内存延迟。
GEMM 优化
技巧1,global->shared memory,采用了texture内存,将线程划分,一半线程只读A,一半线程只读B。
技巧2,shared memory->register,将8×8的读取变成4个4×4的读取,从而避免bank冲突。
对于Maxwell架构而言,相对来说更加简单一些,bank index即reg_index%4这么一个简单的关系。Pascal架构和Maxwell架构的寄存器bank映射关系一样。而volta架构又有一些不同,在volta之前都是4路的bank,而volta架构变成了2路的bank。