基本信息:
Transparent GPU Sharing in Container Clouds for Deep Learning Workloads
代码:TGS
**NSDI 23 **
作者:
- Bingyang Wu and Zili Zhang, Peking University;
- Zhihao Bai, Johns Hopkins University;
- Xuanzhe Liu and Xin Jin, Peking University
简介:针对容器云场景 DL workload GPU 利用率低的问题,提出了 TGS(Transparent GPU Sharing),实现了高 GPU 利用率以及性能隔离。
关键技术:
- adaptive rate control
- transparent unified memory
效果:
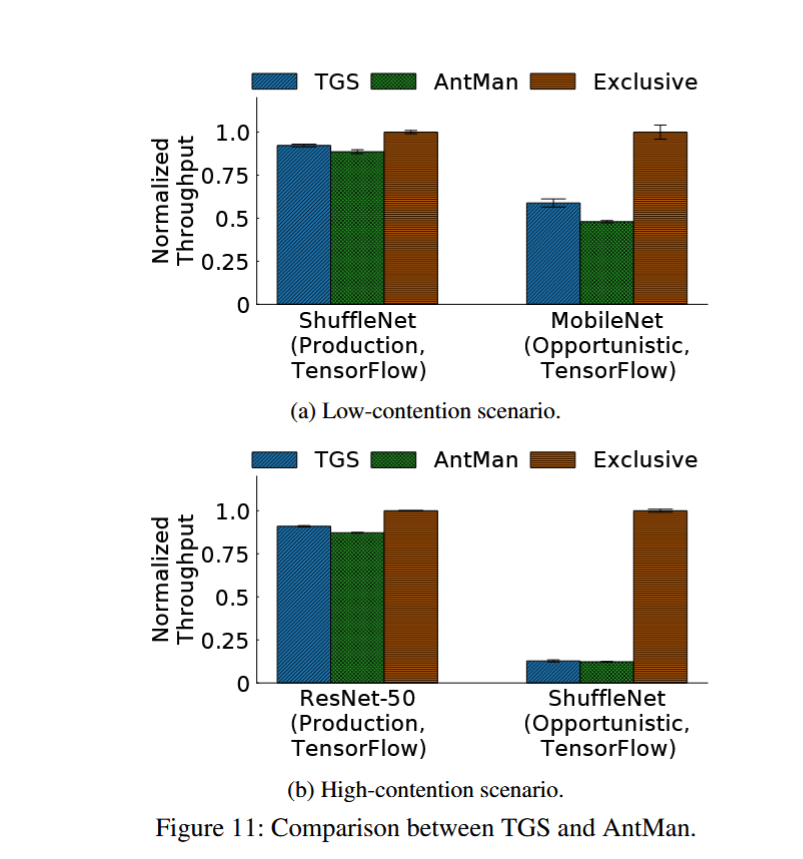
- 对于现有生产任务吞吐影响低。
- 对于投机任务吞吐可以和 AntMan 媲美。
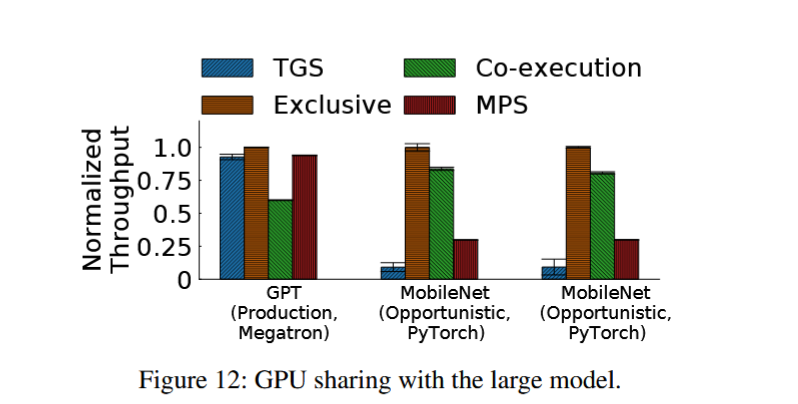
- 吞吐是 MPS 的 15 倍。
背景与动机
1. 在容器云场景中,常见的支持 DL 的做法是容器与 GPU 静态绑定,独占该 GPU。这导致了 GPU 利用率低。
- 数据:微软某个生产环境 GPU 集群利用率为 52%;阿里某个集群 GPU 中位数利用率不超过 10%。
2. 生产环境中 DNN 训练任务通常分为两类,需要保证任务之间不互相影响:
- 生产任务(production jobs):需要保证性能
- 投机性任务(opportunistic jobs):利用闲散资源
3. 先前解决方案局限性
- AntMan:应用层解决方案,需要与框架结合
- MPS:OS 层解决方案,需要感知到应用行为,不支持显存超分场景下的 GPU 共享,多个进程之间不能进行故障隔离。
- MIG:需要 GPU 硬件支持,无法动态分配。

TGS 设计与实现
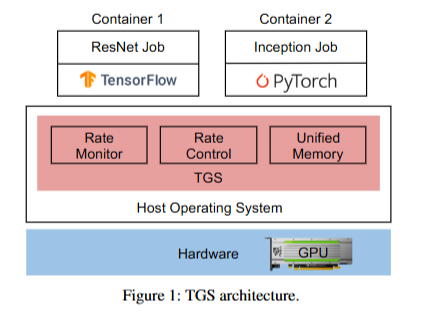
TGS 架构
adaptive rate control
- GPU 共享场景不适用基于优先级队列的任务调度方案,因为 GPU kernel 在 GPU 执行的时候,任务队列可能是空的。
- TGS 核心思想:根据生产任务 kernel 到达速率,控制投机型任务下发 kernel 速率。
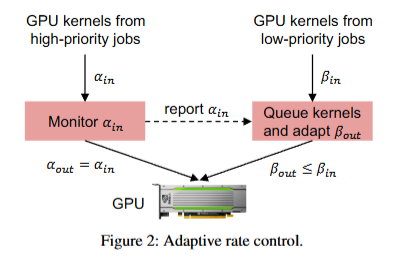
- 通过 additive increase multiplicative decrease (AIMD) 方式控制投机型任务的速率

- TGS 使用了一个全局计数器来记录特定时间内启动的 CUDA block 数量,以此作为控制速率的信号。
transparent unified memory
- 利用 UVM api 做超分。
- 优先为生产任务分配 GPU 内存。当 GPU 内存占满时,TGS 会将投机型任务驱逐到 Host 侧内存上。
实现
3k LoC 的 C++ 和 python,与 Docker 和 K8s 做了集成。
评估
Testbed:Intel Xeon Silver 4210R CPU,2块 A100 40G GPU,126G 内存。
**Trace: **Philly Trace from Microsoft [Jeon et al. 2019]
workload:
• CV: ResNet, ShuffleNet, MobileNet
• Graph: GCN
• NLP: Bert, GPT-2
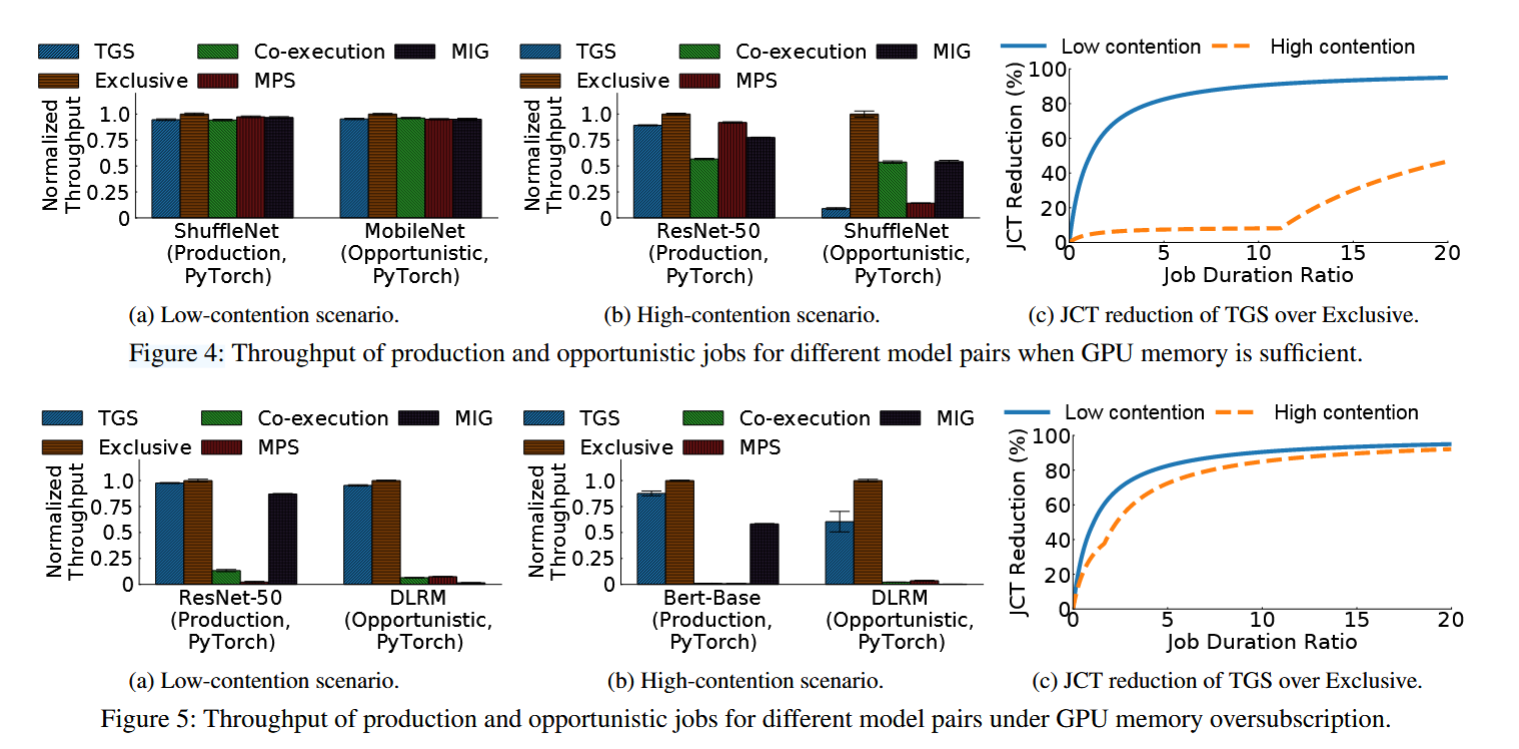
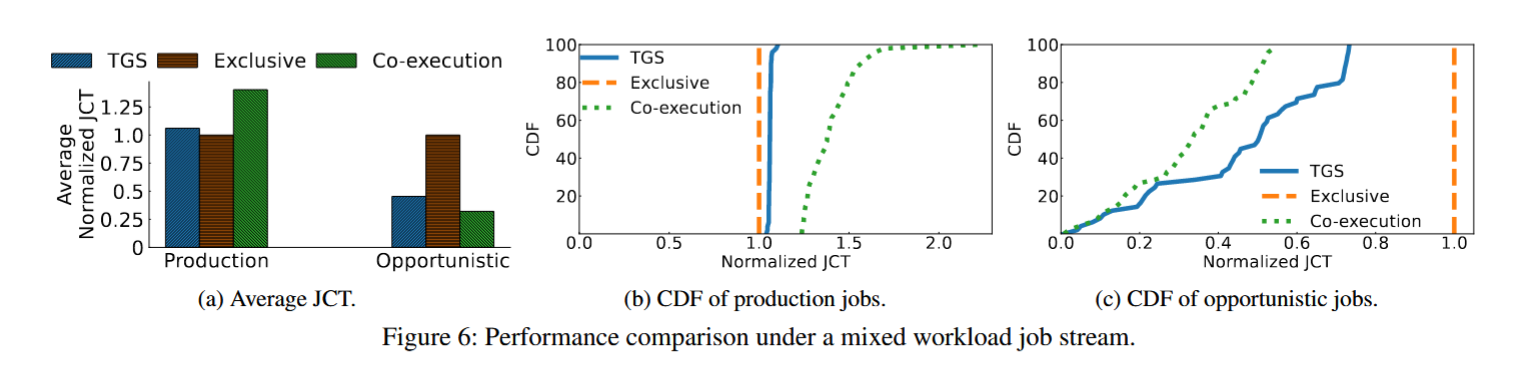
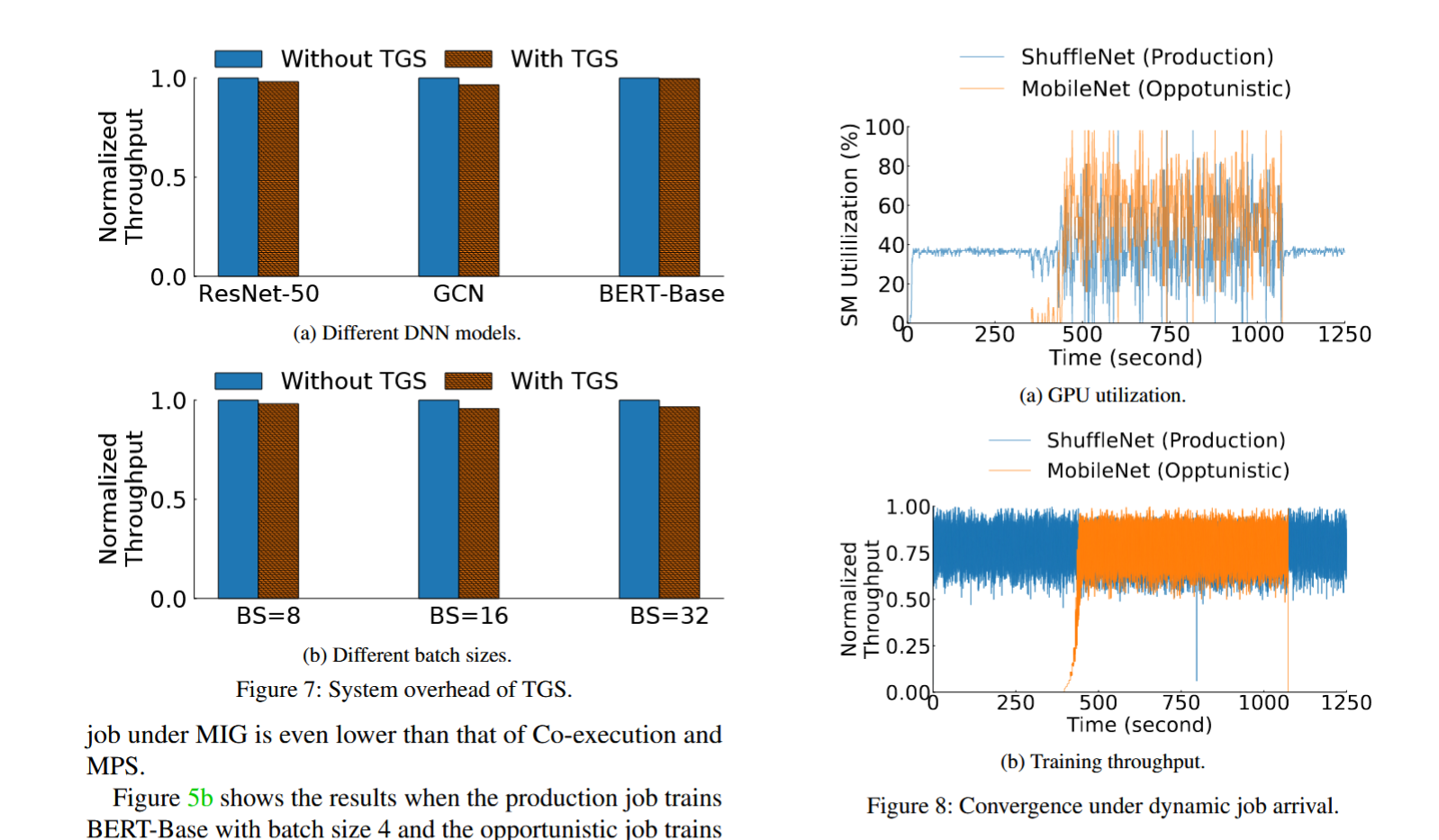
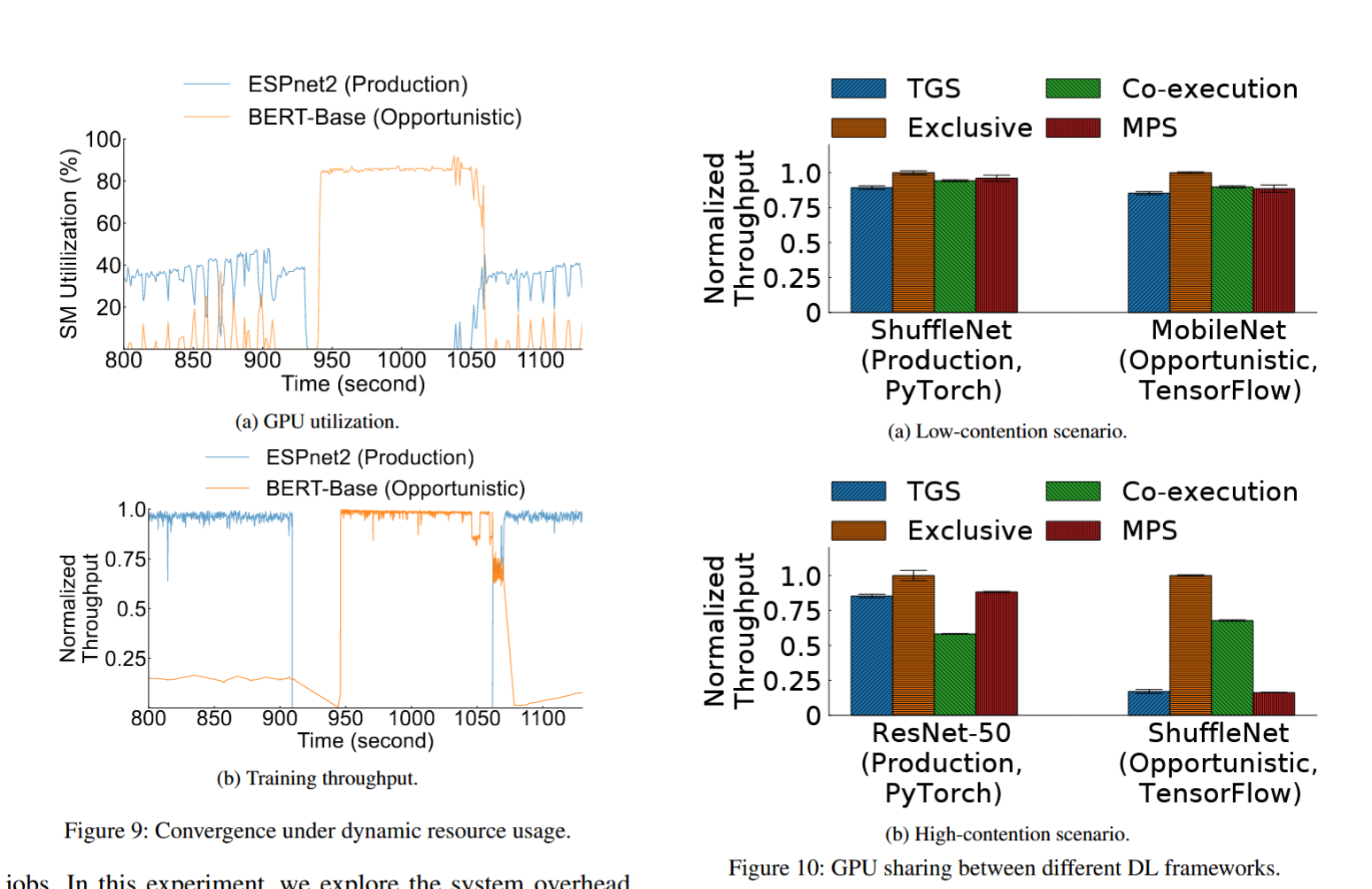
• Recommendation: DLRM实验对比项:每个 workload 运行 100s 测吞吐(iter/second),吞吐方差和 JCT(job completion time)。