基本信息
论文地址:https://dl.acm.org/doi/pdf/10.1145/3731569.3764818
- 作者:
- Patrick H. Coppock, Brian Zhang, Eliot H. Solomon, Vasilis Kypriotis, Leon Yang†, Bikash Sharma†,
Dan Schatzberg†, Todd C. Mowry, and Dimitrios Skarlatos
- Carnegie Mellon University, †Meta
- 简介:针对 GPU 在生产服务中利用率低,能耗高,隔离性差的问题,提出面向 GPU 场景的操作系统 lithOS。
- 关键技术:
- a novel TPC Scheduler 支持任务空分复用
- a transparent kernel atomizer 减少头阻塞,允许在执行过程中动态分配资源
- a lightweight hardware right-sizing mechanism 动态确定每个原子所需的最小 TPC 资源
- a transparent power management mechanism 电源管理机制,降功耗
- 效果
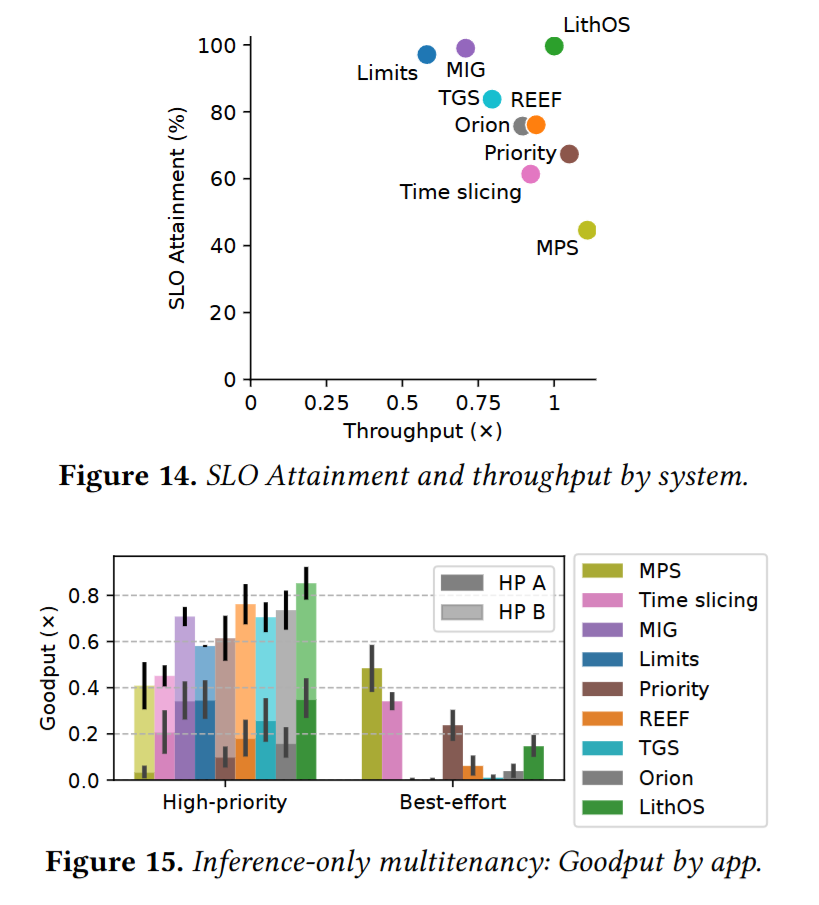
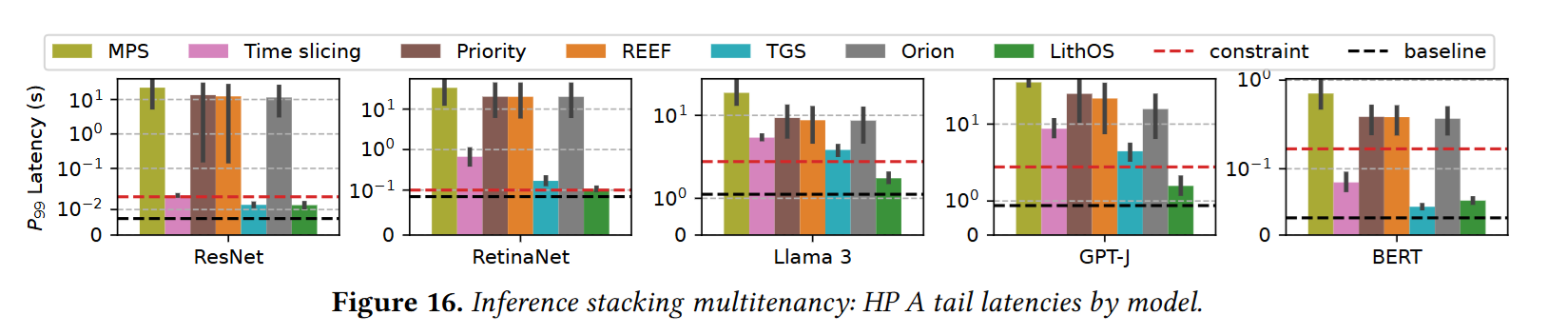
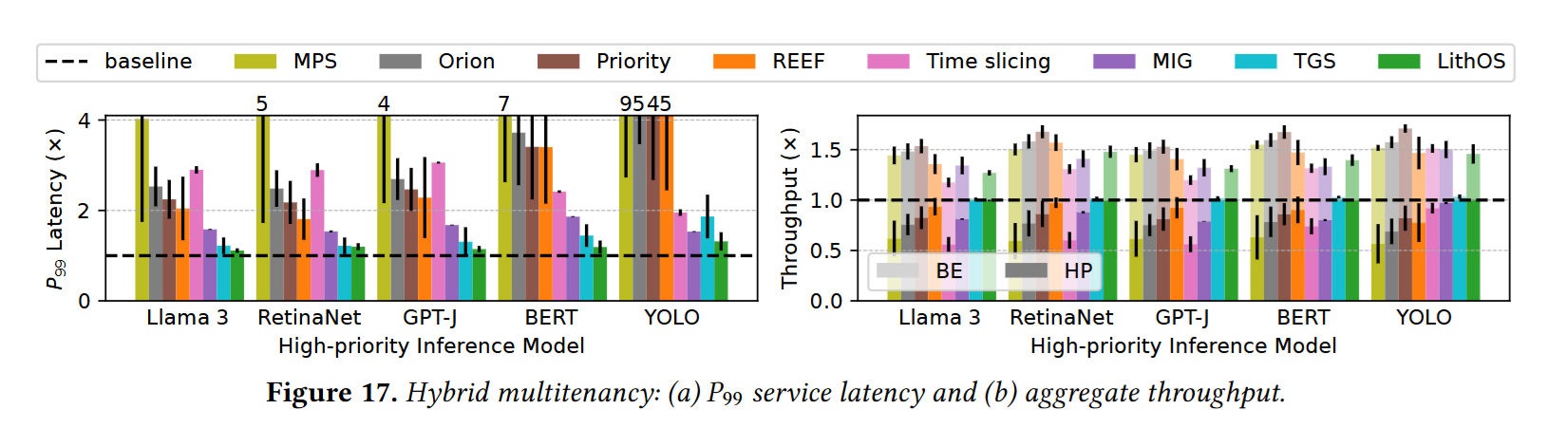
- 推理任务:相比 MPS 将尾时延降低 13 倍,相比 SOTA 将尾时延降低 4.7 倍,有效吞吐提升 1.3 倍
- 训练推理混布场景:相比 MPS 将尾时延降低 4.7 倍,相比 SOTA 将尾时延降低 1.18 倍,有效吞吐提升 1.35 倍
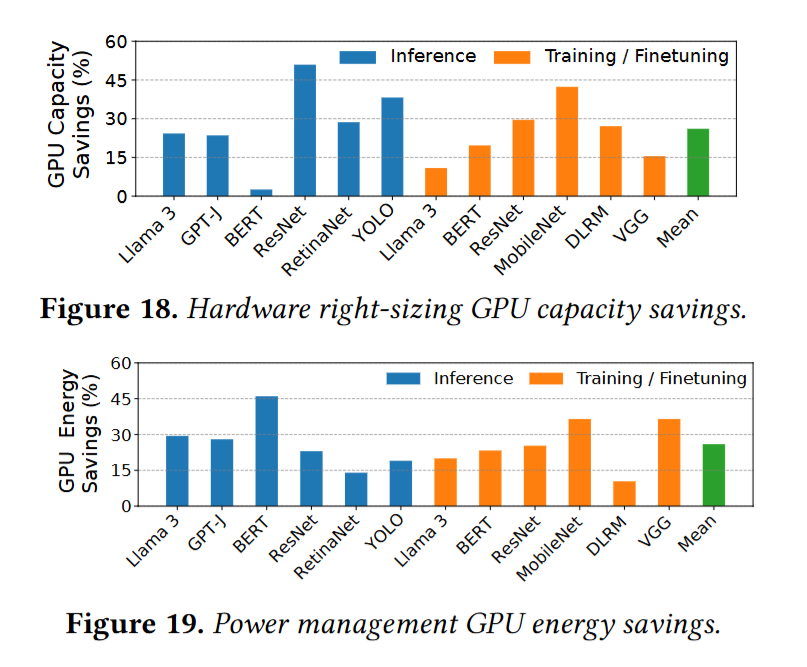
- 在性能损失不超过 4% 的情况下,GPU 资源节省 25%。
- 在性能损失不超过 7% 的情况下,GPU 能耗节省 25%。
背景与动机
背景
GPU 任务通常被分为 latency-critical (LC) 型和 best-effort (BE) 型。在 LC 和 BE 任务争抢资源时,现有系统不能针对优先执行 LC 任务这点提出很好的解决方案,且许多方法缺乏透明度。
现有解决方案
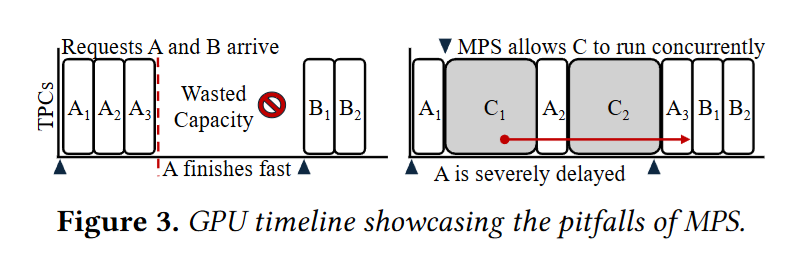
- TGS,Clockwork:无法并行执行多个模型
- MPS,MIG,REEF,Orion:支持多个应用并行执行,但粒度过于粗糙,会对整个推理请求,训练批次或 DNN 算子进行调度,导致利用率低、头阻塞问题。
动机
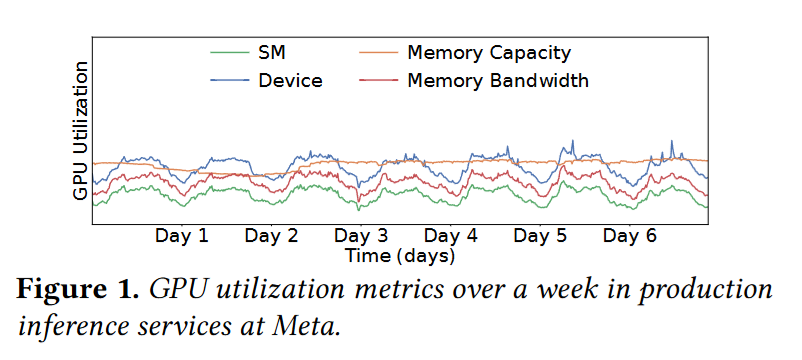
观测了 meta 跑在 H100 上的推理服务运行情况,发现:
设备利用率在 25% - 60% 之间,SM 利用率低于 15%,内存也通常不会占满。为了保证 SLA,会采用小 batch size,这样 GPU 利用情况会比较稳定。表明多租场景有利用率提升空间
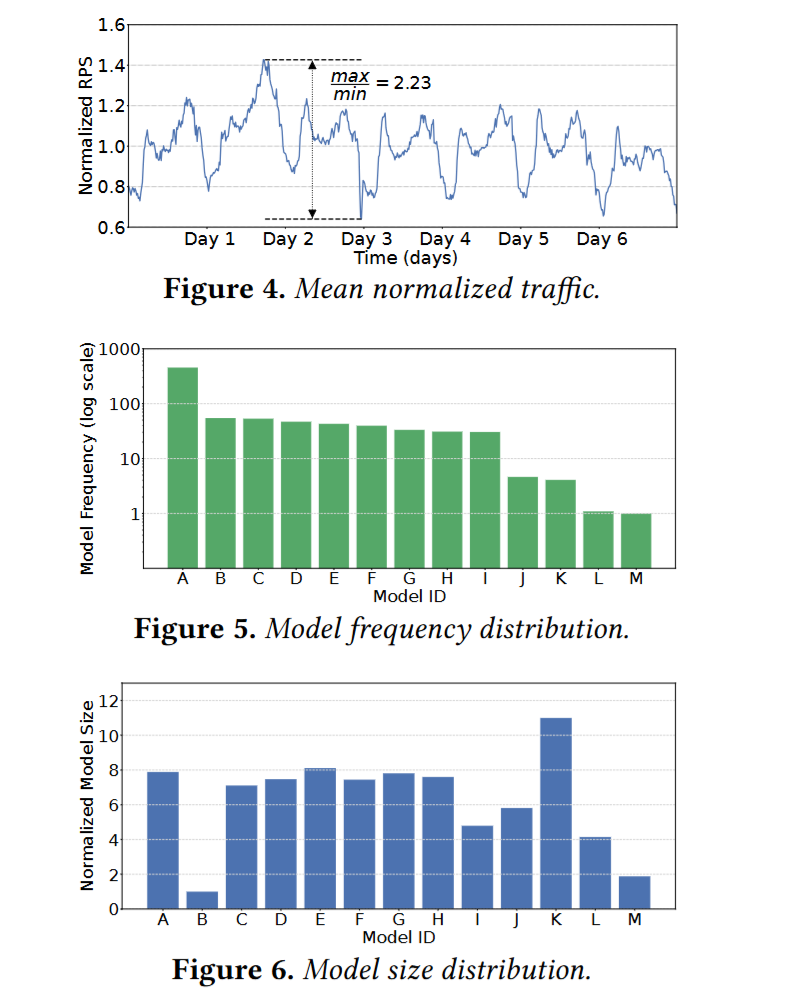
推理流量情况呈现昼夜周期重复迹象,大小模型都可能有比较高的使用频率。表明不同模型之间根据模型大小、使用频率进行排列组合搭配使用是有收益的。
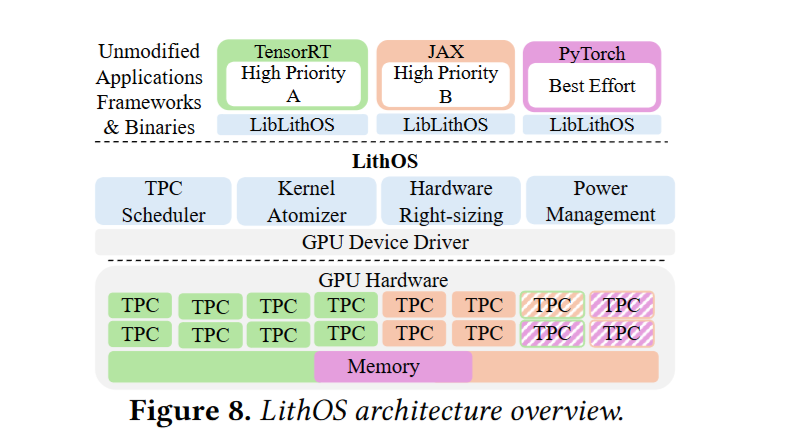
LithOS 设计与实现
像操作系统那样对于任务进行调度可以有效提高资源利用率,降低功耗。所以 GPU 管理模式必须向操作系统模型演进。
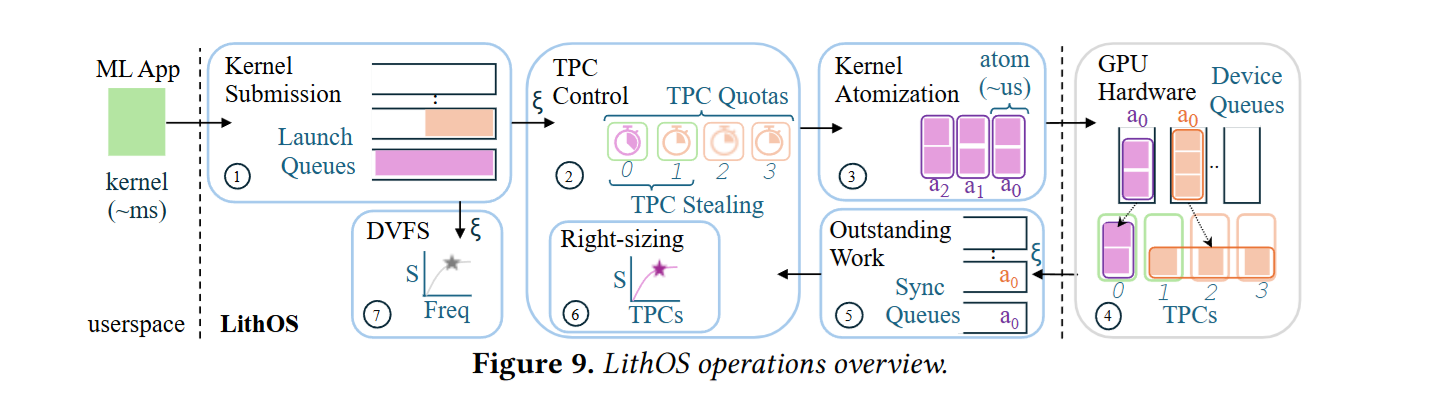
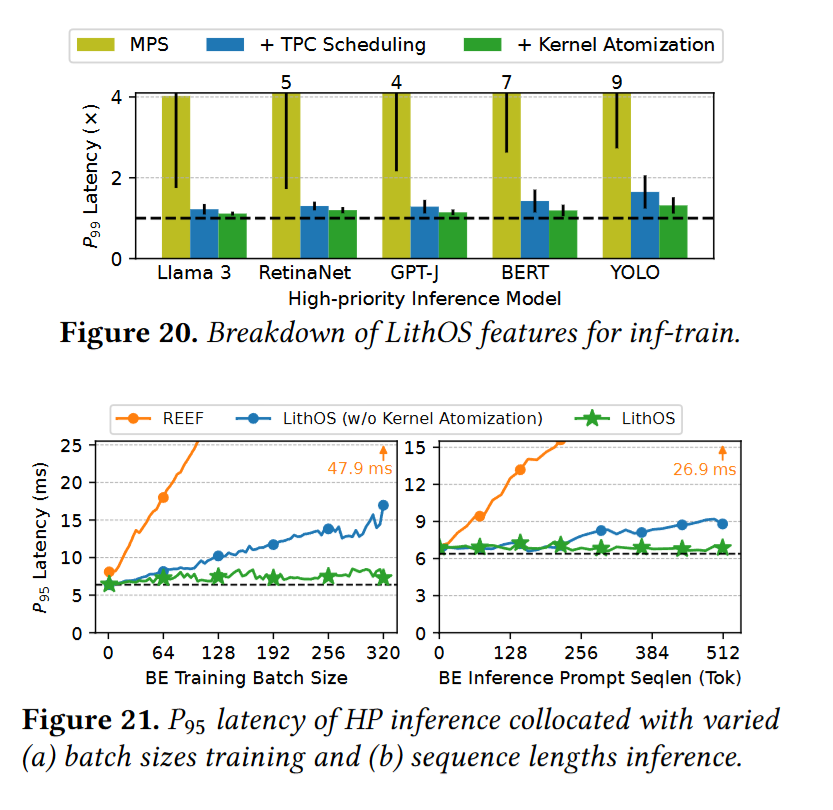
TPC scheduler
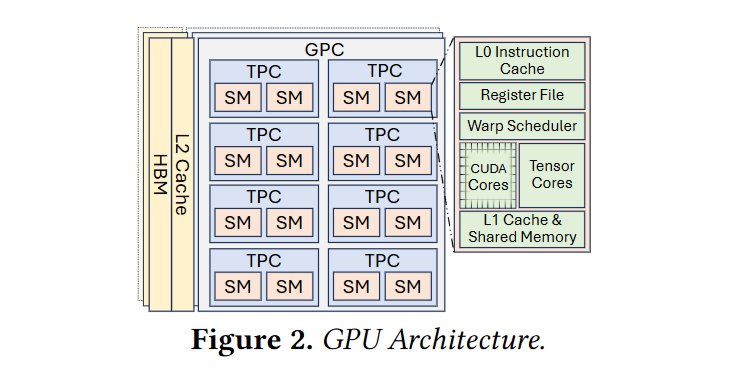
- LithOS 任务运行粒度是 kernel thread block 级别,会被动态映射到 GPU 的 Texture Processing Clusters (TPCs),LithOS 以 TPC 为粒度来管理资源。
TPC 是什么?
GPU 架构:数个 Graphics Processing Clusters (GPCs) -》数个 TPC -》几个 SM 核
比如 H100 组成:8 GPC -》 9 TPC -》 2 SM -》 128 cores
latency prediction module:通过在线学习并预测每个 atom 执行时间,从而指导调度器进行 tpc stealing 利用空闲的 TPC。
- 调度器只允许执行时间非常短的 atom 去做 tpc stealing
拓展了 libsmctrl.so 来操作 TPC 映射
Kernel Atomizer:
- LithOS 通过 Prelude Kernel 技术,在 Kernel 启动前会将其分解为 thread block 来进行独立调度执行,每个 tb 被称为 atom。
- 高优先级任务到来时,调度器等当前 atom 完成后就优先执行高优先级任务,做到模拟抢占
- 修改了启动内核的 QMP struct 来注入 prelude 逻辑。
hardware right-sizing mechanism
- 基于一个只需要两个数据点的并行计算模型(l = m/t + b)进行在线建模,来知道每个 Kernel 性能随 TPC 变化的曲线,从而做到硬件资源精简,限制分配上限。
transparent power management mechanism
- GPU 在执行内存密集型任务可以降频省电。
- 通过 sequence-based kernel frequency scaling model,计算一系列 kernel 的统一目标频率
代码实现
- ~5k LoC Rust
评估
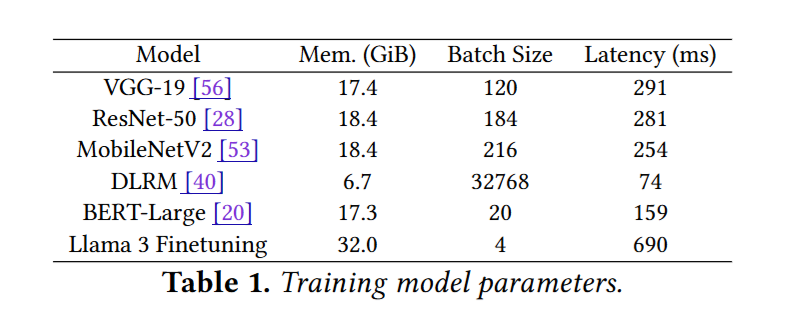
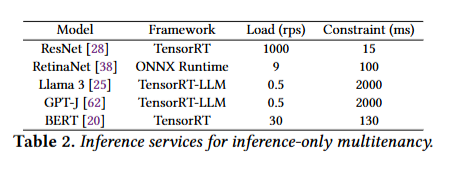
Testbed: 1 40G A100,30 CPU,216G 内存
workload: