https://huggingface.co/spaces/Ki-Seki/ultrascale-playbook-zh-cn
介绍 LLM 分布式训练中所使用的技术
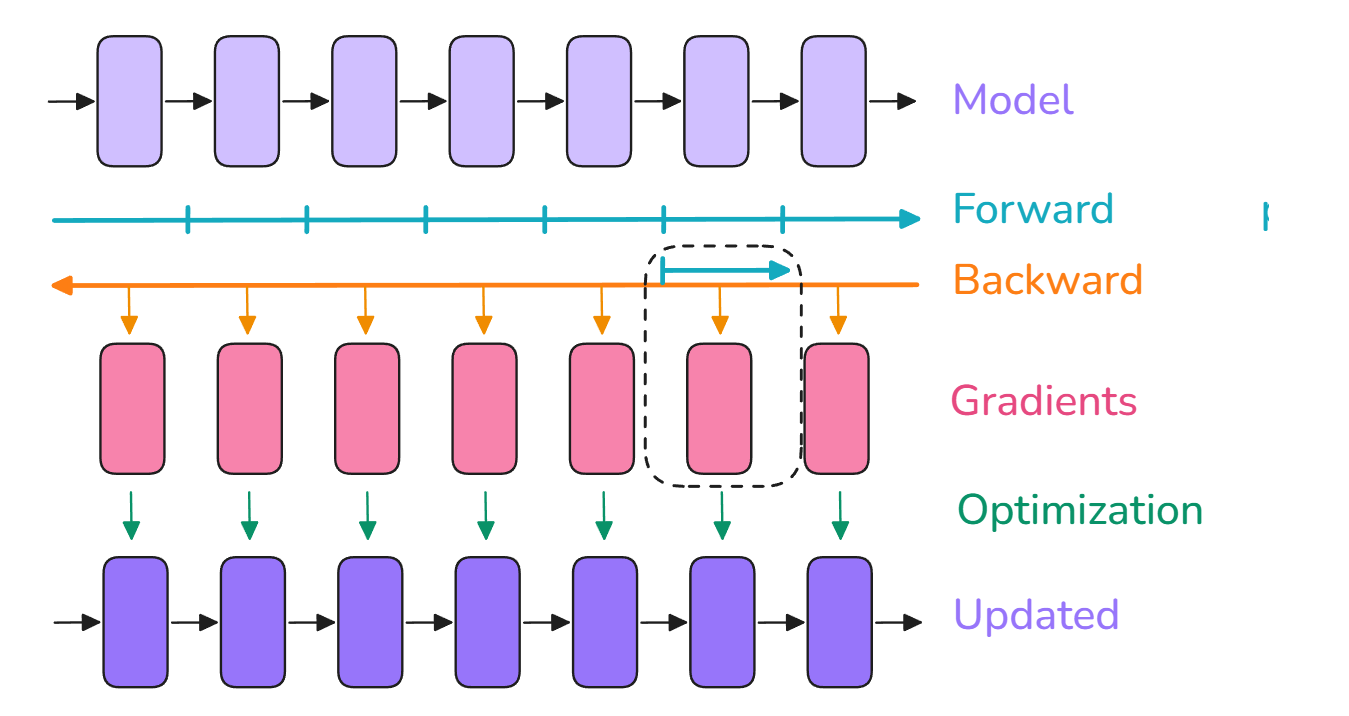
单卡训练
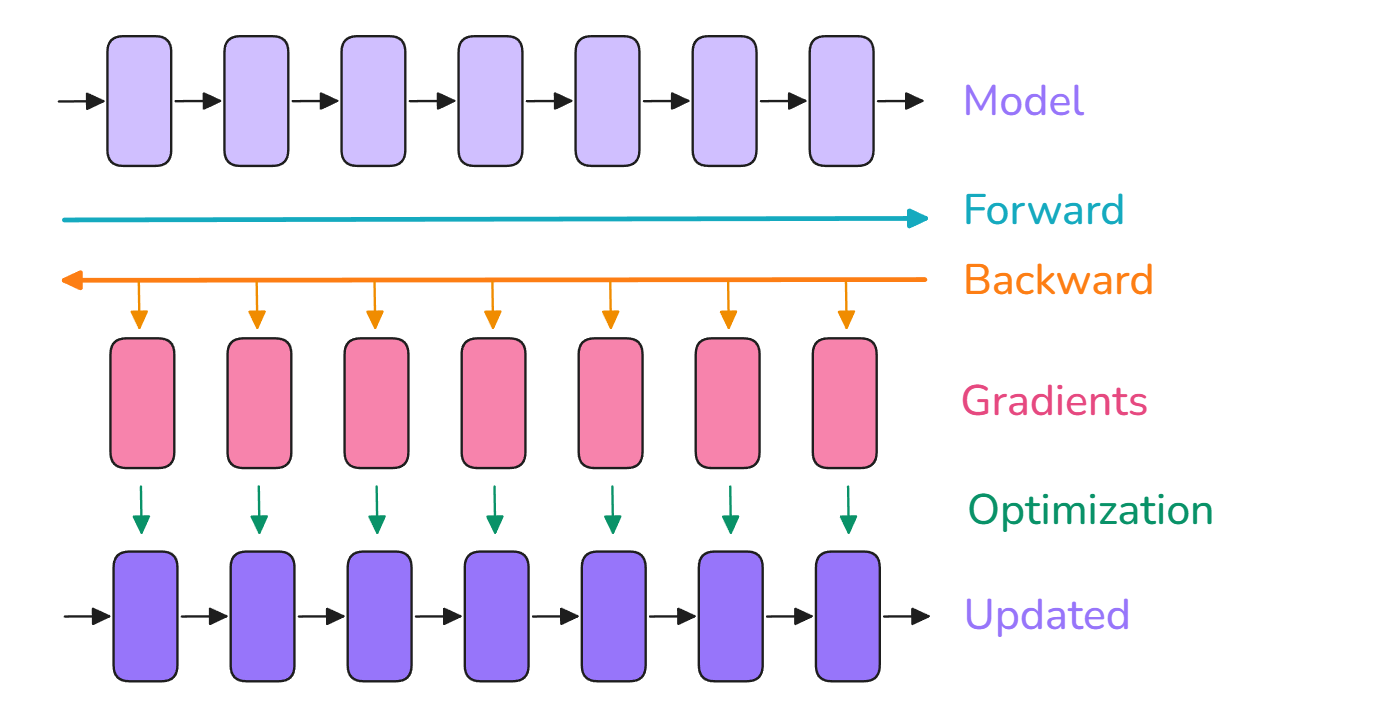
单卡训练基本流程
- 前向传播(forward pass):输入模型以数据,得到输出
- 反向传播(backward pass):计算梯度
- 优化步骤(optimizer step):利用梯度更新参数
- Batch size
Batch size(bs)是模型训练中重要的超参,会影响模型收敛及吞吐
小 bs 有利于训练初期快速更新权重,且梯度带有随机性,但训练后期,小 bs 可能使梯度噪音过大无法收敛。
bs 过大,虽然可以让梯度估计更精确,但每次更新代价增大,影响效率
—— 参考 OpenAI 大 bs 训练论文,或 MiniMax-01 技术报告
LLM 预训练中, bs 通常会用 token 而不是样本量来表示(bst = Batch Size Tokens)。最简单的单机训练场景中,bs 和 bst 可以通过序列长度相互转换:
bst = bs * seq
常见的 bs 大小:Llama 1 大约用 4M bst,训练了 1.4T token 数据;deepseek 用 60M bst 训练了 14T token。
Transformer 中显存的使用
训练中一般需要占用显存的(其他还有零散的需要占用显存的固定开销暂不考虑):
- 模型权重(weights)
- 模型梯度(gradients)
- 优化器状态(optimizer states)
- 用于反向传播的激活值(activations)
这些一般以张量形式存在,不同张量有不同形状 shape 和精度 precision。
决定形状的超参因素: bs、seq len、模型隐层维度、注意力头数、词表大小、是否进行模型切分等
精度:FP32、BF16、FP8 等
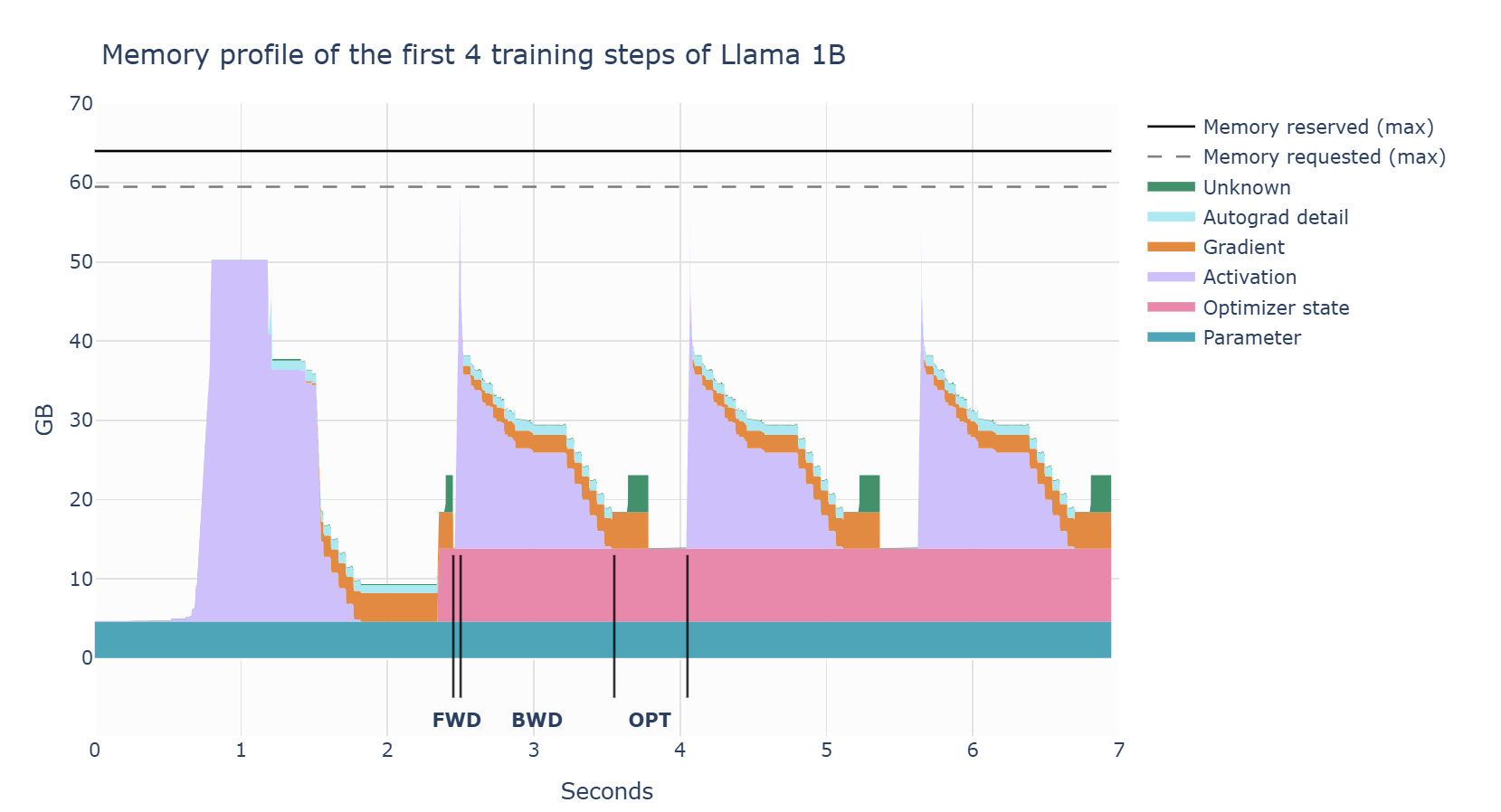
- 前向传播时,随着激活值的产生,显存快速上涨
- 反向传播时,梯度逐渐累加,用于计算梯度的激活逐步释放
- 优化步骤时,需要所有梯度,然后更新优化器状态
第一步里激活快速增加,然后有一段时间保持在高位。这是因为 Torch 的 allocator 要初始化分配显存块,虽有训练步骤中不必再频繁搜索可用显存(Zach 博客)。第一步结束后,还需要为优化器状态分配显存。
估算 LLM 训练中显存占用
N = h * v + L * (12 * h^2 + 13 * h) + 2 * h
其中 h 是隐层维度,v 是词表大小,L 是层数。
如果以 FP32 (4 byte)进行训练,优化器使用 Adam,则总显存占用:
Mparams = 4 * N
Mgrads = 4 * N
Mopt = (4 + 4) * N
如果采用混合精度 BF16,则参数和梯度需要 2 byte,同时保留一份 FP32 的权重和梯度副本,因此每个参数需要 12 byte。优化器状态通常为了稳定性考虑,也是以 FP32 进行存储:
Mparams = 2 * N
Mgrads = 2 * N
Mparams_fp32 = 4 * N
Mopt = (4 + 4) * N
有些库会把梯度以 FP32 额外存储一份,则需要额外 Mparams_fp32 = 4 * N 空间,目的是为了稳定性,防止混合精度对较小值的损害。
有时会把这份权重副本称作“master weights”。
混合精度本身可能并不会减少总体显存需求,甚至如果多保存一份梯度副本的话,整体开销还会涨。但低精度前向/反向计算速度变快了,且前向中激活占用减少了。这在大 bs 或长序列中尤为重要。
常见模型存储量级:

可以看见 7B 以上规模时,仅权重和优化器状态就已经超过许多 GPU 显存了。
激活值占用
激活值需要在反向传播时用来计算梯度。它的占用会受到输入影响。激活值占用参考估算 Nvidia 重计算论文:
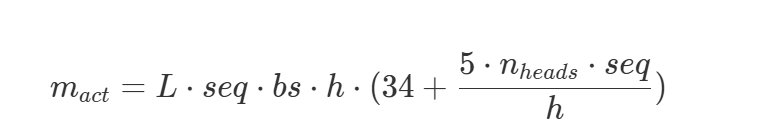
激活值占用会随序列长度 seq 及 bs 线性增长:
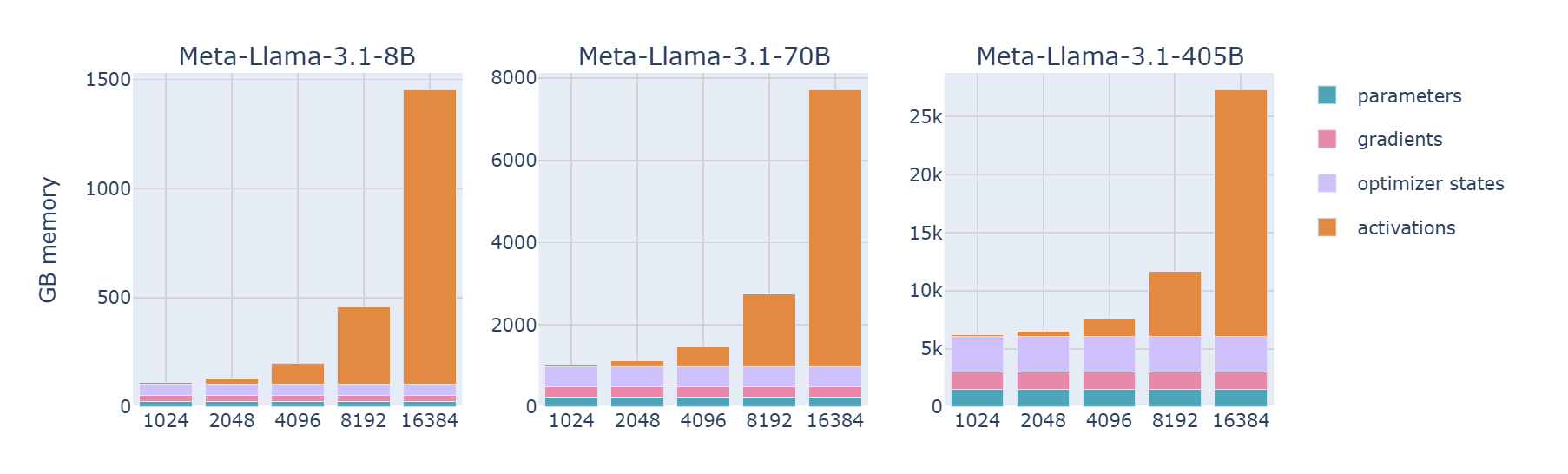
可以看到,对于大输入 tokens,激活值是主要负担,可采用激活重计算(Activation Recomputation)来限制显存占用。
激活重计算(Activation recomputation)
前向传播时丢弃部分激活值,在反向传播时再做一次子前向过程计算回来。
实际实施的时候有以下几种策略来决定哪些激活需要保存:
- Full 重计算:每层 transformer 中只保存输出激活值,舍弃中间激活。这样相当于在反向时重跑轮前向,大约多 30-40% 计算量,但完全消除了激活值的显存占用。
- Selective 重计算:Nvidia 重计算论文对激活值大小与重计算 FLOPs 成本进行分析后发现,attention 的激活值往往更大,且其重计算所需 FLOPs 相对 feedforward 更少。比如对 GPT-3 (175B)模型来说,可以在 2.7% 额外计算成本下减少 70% 的激活值显存。
- DSv3 使用了 Multi-Head Latent Attention(MLA)进一步优化激活内存。

越小模型(h 较小)在长序列(seq)较大下,激活值占比越大,重计算收益越明显
在测量利用率时,一般要把重计算计算量纳入总 FLOPs 中,再和理论峰值 FLOPs 进行对比,以得到实际硬件 FLOPs 利用率(Hardware FLOPS Utilization, HFU)
但我们往往更关注端到端训练所需总时间。对于有足够显存能跳过重计算的硬件来说,HFU 降低了,但训练速度更快。因此仅统计模型本身前后项所需 FLOPs 来计算 Model FLOPs Utilization(MFU)更有意义。
当今训练框架中,FlashAttention 已经成为了注意力优化的标配,它在反向传播中就会自动重算注意力得分和中间矩阵,而不存储它们,这本质上时 selective 重计算的一种。
小结
激活重计算用 2-30% FLOPs 的代价换来了显存占用大幅降低。
梯度累加(gradient accumulation)—— 优化大 global batch size 下的峰值内存
梯度累加用于避免过大 bs 导致的显存爆炸。它做法是:将原本一次大 batch 拆成多个更小的 micro-batch 分别进行前后向计算梯度,然后将梯度累加起来再汇总做一次优化器更新(optimizer.step)。
每次前向使用的 bs 称为 micro batich size(mbs),全局 batch size (两次 optimizer step 之间)称为 global batch size(gbs):
bs = gbs = mbs * grad_acc
梯度累加的 trade-off
通过多次前反向计算,减少激活峰值内存占用(存储累计梯度需要点额外缓冲区占用)。
不过每个 mbs 实际上是可以并行运行,前反向传播彼此独立,唯一区别在于输入样本是独立的。
Pytorch profiler —— 可视化计算和通信情况
1 | with torch.profiler.profile( |
这会生成一份 trace,可以在 TensorBoard 或 Chrome tracing viewer 中查看: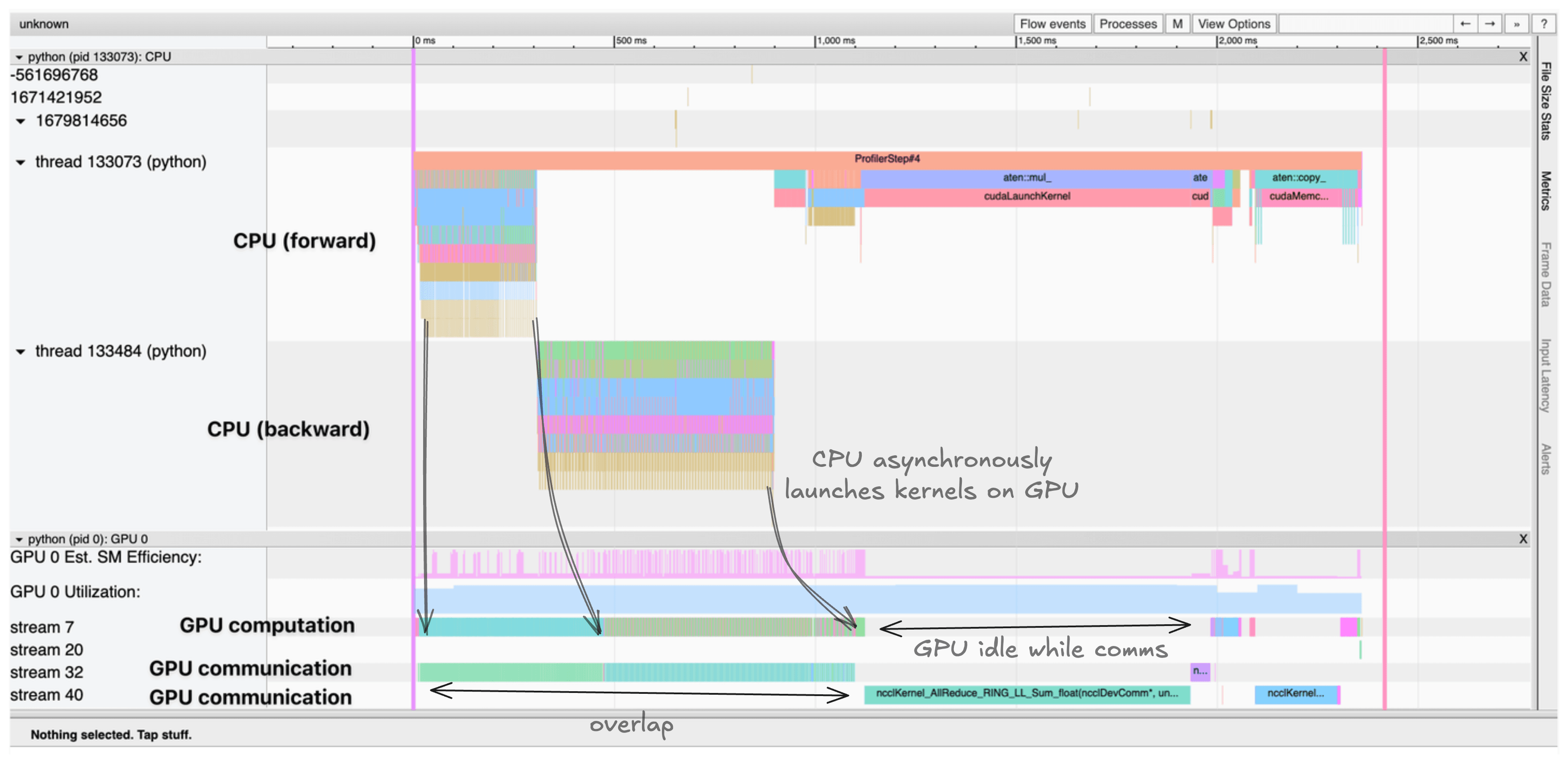
-