GPU-Initiated Networking for NCCL
NCCL 2.28 版本支持了在 Device 侧直接发起通信的 KI-GDA 能力,性能和通过 NVSHMEM 实现的基本一致。
本文是对其技术报告的笔记总结。
整体架构
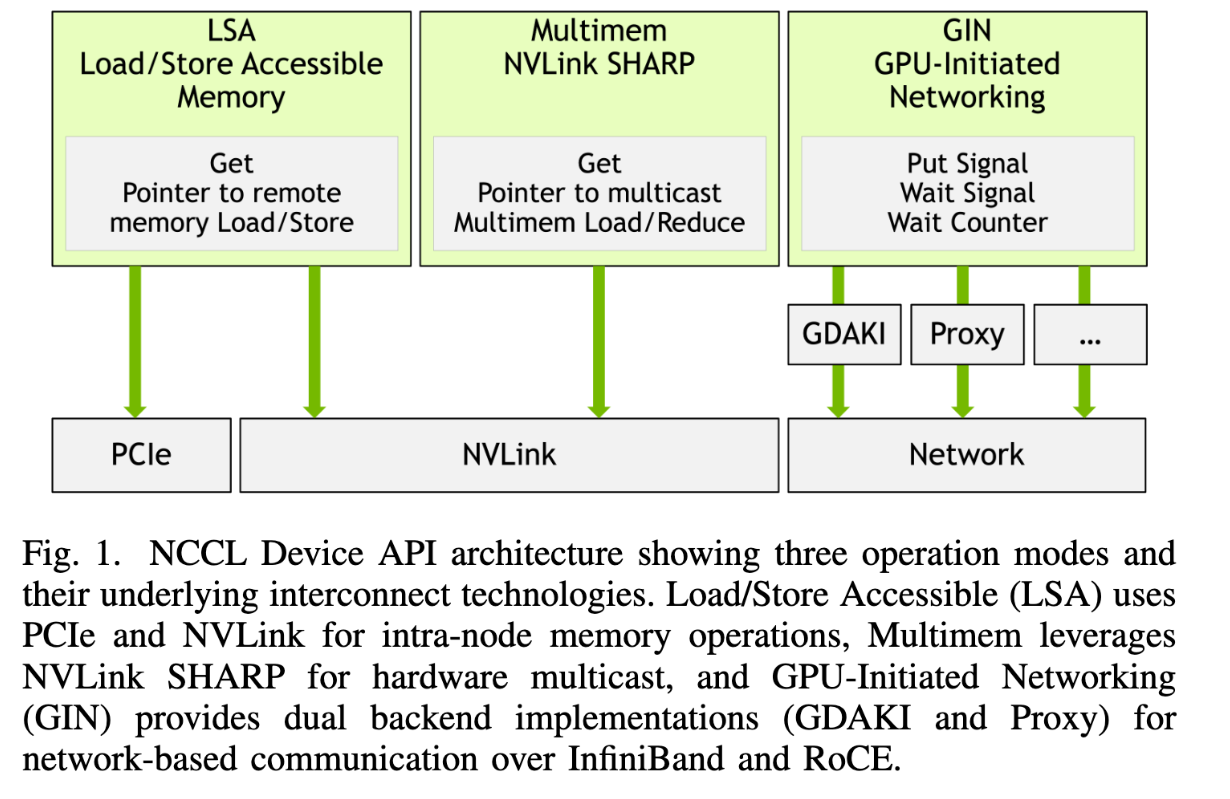
Device API 新的三种操作:
- LSA load/store accessible memory: get, remote memory load/store,用在 PCIe 或者 NVLink
- multimem nvlink sharp: get,remote mem load/reduce 操作,用在 nvlink
- GIN: put signal,wait signal,wait counter,用在 network
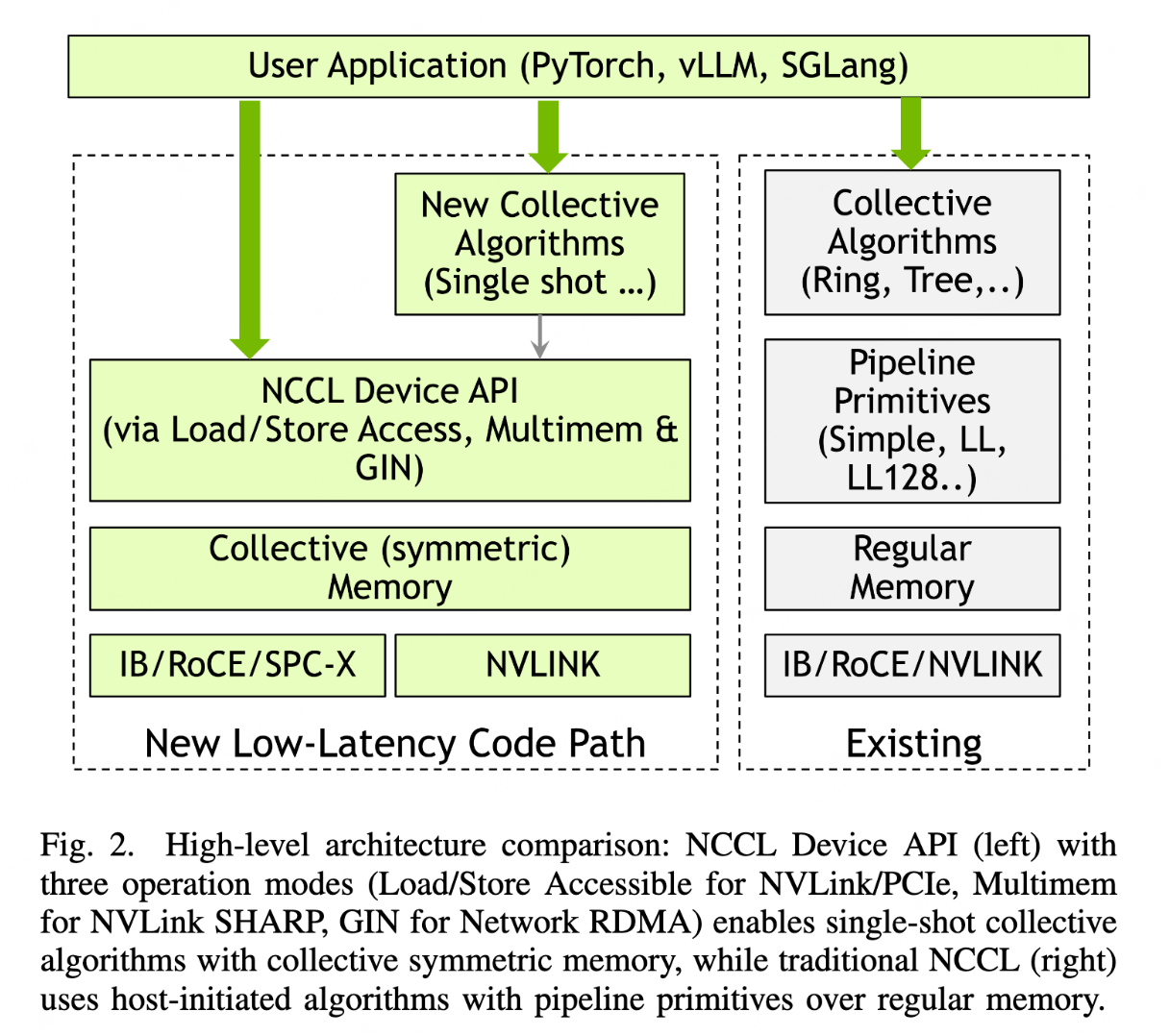

GIN 可以用新的 single shot 集合通信算法,或者直接用 device api 原语
GIN 特性细节:
- 支持线程级/warp级操作,imm 操作,window-based mem addr,local counter /remote signal同步机制
- proxy:lock-free GPU-CPU 的 64 byte descriptors queue
- GDAKI:使用 DOCA GPUNetIO backend
- 使用 window mem,每个rank有一块 local buffer 和 receives handles。每个 rank 都必须注册自己的 comm buff,遵循 MPI RMA window model。每个 rank 支持注册不同大小的 buff(比如 prefill 更大,decode 更小),但当前 2.28 版本不支持
- 和 DeepEP 做了集成,证明能和 NVSHMEM 有近似的性能
- 走 GDAKI 需要依赖 CX6 以上的网卡或者 BlueField 系列 DPU,不然只能降级成 proxy 模式
- GIN 还需要依赖 nv_peer_mem 内核模块来使能 GDA,还有 OFED
- GPU 和 NIC 在同一 pcie root complex 能性能最好(DGX 那种一个 GPU 和一个 NIC 绑定那种)
- 基于单边操作,提供 put、put with signal 接口
- proxy 接口下,NCCL core 实现控制面结构,任务队列,device api impl;plugin 定义 put、signal、test、tegMr 接口
- GDAKI 接口下,plugin 通过 createContext 创建 gpu ctx,数据面借助 Kernel-initiated API
- 网络,不同 ctx 使用不同网卡,不同 qp,不同 stream
- 本地完成通知 counters,本地发送完成计数器,表明发送 buffer 用完了;flush 所有操作都已经 posted to the ctx
- 远端完成通知 signal,使用 ID-based addressing,用 id 来标识自己(替代 openshmem 都 address-based sync)
- GIN 操作是乱序的,只有同一 ctx 下的 put 和 signal 操作是保序的(多个 put + signal)
- flush 操作只保证本地操作是完成的,远端收没收到不保证
- GDAKI 实现细节:put 操作发起时,gpu 线程写 wqe,然后写 nic db。cq 是 gpu-visible mem 上的
- proxy 实现细节:put 操作时,GPU thread enqueue op descriptor int lock-free queue。CPU 线程 poll 队列,通过 iput/iput signal 接口来发包。在 GPU-visible mem 中更新完成状态

API 及使用


